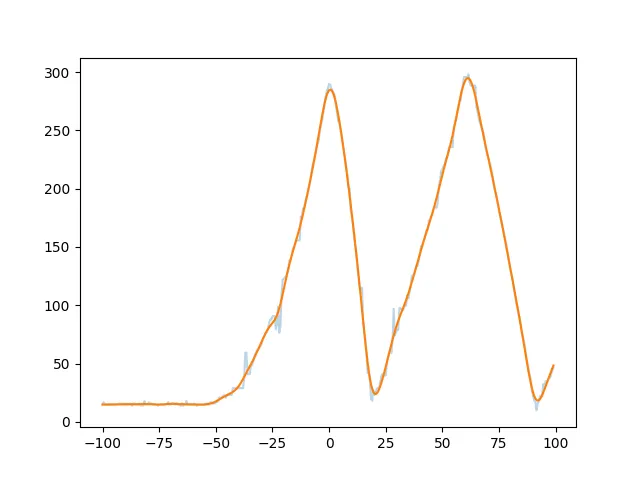
我有一个带有一些异常值(错误的测量数据)的图表:
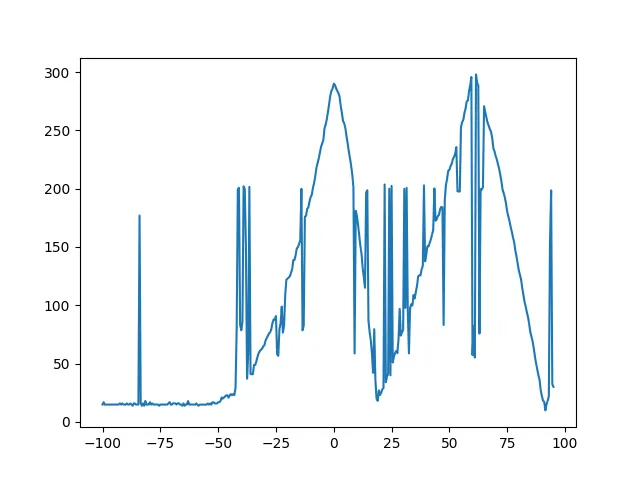
pd.rolling().mean(),但没有令人满意的结果:import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
data = np.genfromtxt('shard_height_plot.csv', delimiter = ',')
df = pd.DataFrame(data)
df.set_index(0, inplace = True)
df2 = df.rolling(20).mean()
plt.plot(df)
plt.plot(df2)
plt.show()
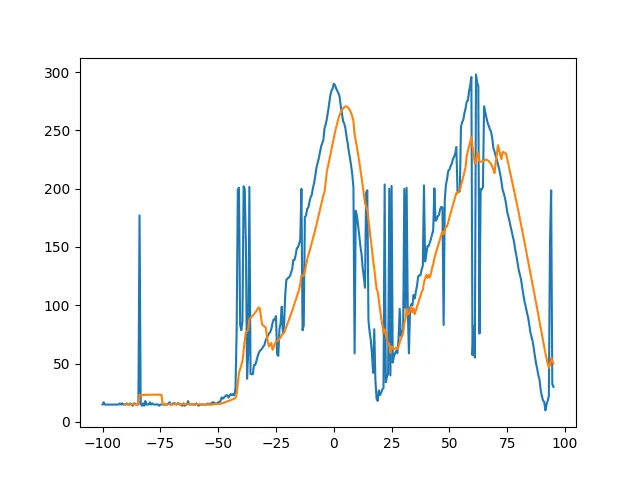
我试图在网上寻找一个好的解决方案,但是没有找到。删除掉突然暴增的数据点不应该很难吧?
编辑:数据文件可以在这里下载:https://ufile.io/pviuc
编辑2:
我通过改进我的数据集创建来解决了过多离群值的问题。
核心内容:
if abs(D - D_List[-2]) > 30:
D = D_List[-2]
D_List.pop()
D_List.append(D)
基本上,这个程序会检查一个值的变化是否大于30,如果是,它将删除最后一个值并用倒数第二个值替换它。虽然不是非常惊人,但正是我所需要的。我使用了其中一个答案,因为它更加美观。非常感谢你们。