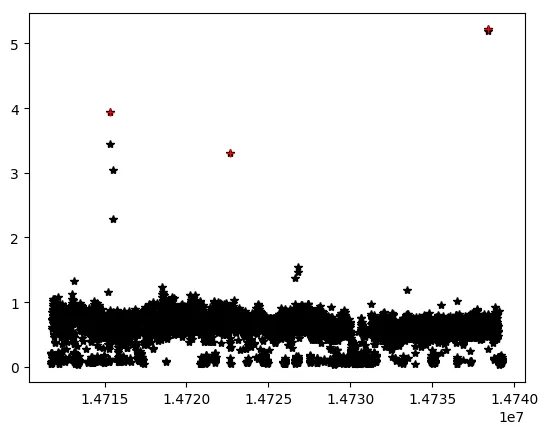
我认为使用scipy.stats.zscore()的z-score方法是解决这个问题的途径。在这篇文章中,他们关注的是在删除潜在异常值之前要使用哪种方法。在我看来,你面临的挑战有点简单,因为根据提供的数据,很容易识别潜在的异常值,而不必转换数据。下面是一个代码片段,可以做到这一点。但请记住,什么看起来像异常值和什么不是完全取决于您的数据集。在删除了一些异常值之后,以前没有看起来像异常值的数据可能会突然变成异常值。请看:
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
from scipy import stats
data = [0.5,0.5,0.7,0.6,0.5,0.7,0.5,0.4,0.6,4,0.5,0.5,4,5,6,0.4,0.7,0.8,0.9]
df1 = pd.DataFrame(data = data)
df1.columns = ['data']
df1.plot(style = 'o')
def outliers(df, level):
df = df1.copy(deep = True)
df_Z = df[(np.abs(stats.zscore(df)) < level).all(axis=1)]
ix_keep = df_Z.index
df_keep = df.loc[ix_keep]
return(df_keep)
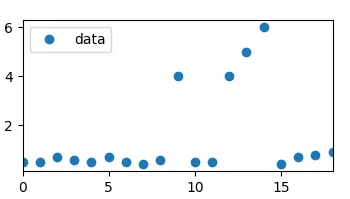
原始数据:
测试运行1: Z得分=4:
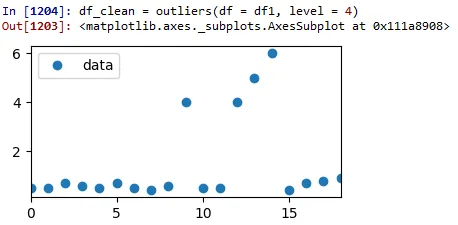
如您所见,因为设置的水平过高,没有删除任何数据。
测试运行2: Z得分=2:
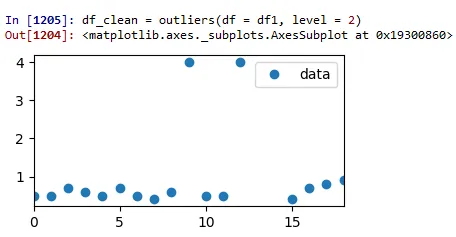
现在我们有所进展。已删除两个异常值,但仍有一些可疑数据。
测试运行3: Z得分=1.2:
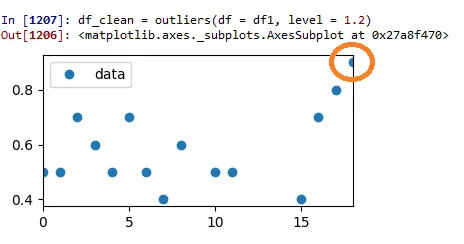
这看起来非常好。剩下的数据现在似乎比以前更均匀分布。但是,原始数据点突出的数据点现在开始看起来有点像潜在的异常值。那么何时停止呢?这将完全取决于您!
编辑:以下是整个内容,供简单复制粘贴:
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
from scipy import stats
data = [0.5,0.5,0.7,0.6,0.5,0.7,0.5,0.4,0.6,4,0.5,0.5,4,5,6,0.4,0.7,0.8,0.9]
df1 = pd.DataFrame(data = data)
df1.columns = ['data']
df1.plot(style = 'o')
def outliers(df, level):
df = df1.copy(deep = True)
df_Z = df[(np.abs(stats.zscore(df)) < level).all(axis=1)]
ix_keep = df_Z.index
df_keep = df.loc[ix_keep]
return(df_keep)
level = 1.2
print("df_clean = outliers(df = df1, level = " + str(level)+')')
df_clean = outliers(df = df1, level = level)
df_clean.plot(style = 'o')