在回答实际问题之前,根据数据的性质,我们应该问另一个非常相关的问题:
什么是异常值?
想象一系列数值[3, 2, 3, 4, 999](其中999似乎不合适),并分析各种异常值检测方法
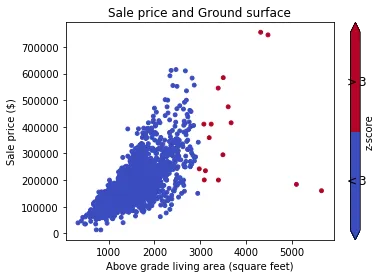
Z-Score
问题在于,所讨论的值严重扭曲了我们的度量方式mean和std,导致Z-score大约为[-0.5, -0.5, -0.5, -0.5, 2.0],保持每个值在平均值的两个标准偏差内。一个非常大的异常值可能会扭曲您对异常值的整体评估。我不鼓励使用这种方法。
Quantile Filter
更为稳健的方法是此答案,消除数据底部和顶部的1%。但是,这样会消除相对固定的一部分数据,而独立于这些数据是否真的是异常值。您可能会失去很多有效的数据,并且另一方面,如果您的数据中有1%或2%以上的数据是异常值,则仍会保留一些异常值。
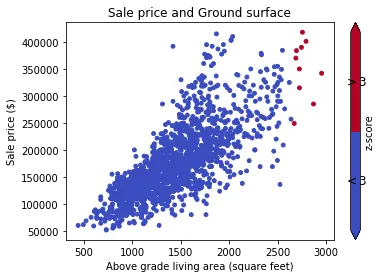
中位数到IQR距离
这是分位数原理的更稳健版本:消除所有距离数据的中位数超过f倍四分位距。例如,sklearn的RobustScaler使用这种变换。IQR和中位数对异常值具有鲁棒性,因此您可以避免Z-score方法的问题。
在正常分布中,我们大约有iqr=1.35*s,因此您将把z-score筛选器的z=3转换为iqr-filter的f=2.22。这将删除上述示例中的999。
基本假设是至少您的数据的“中间一半”有效,并且很好地反映了该分布,而您也会搞砸,如果您的分布具有宽尾巴和一个窄的q_25%到q_75%区间。
高级统计方法
当然,还有一些花哨的数学方法,例如佩尔斯准则、格鲁布斯检验或迪克森Q检验等,也适用于非正态分布数据。它们中没有一个容易实现,因此不再进一步讨论。
代码
将所有数字列的所有异常值替换为np.nan在示例数据框上。该方法对Pandas提供的所有数据类型
import pandas as pd
import numpy as np
df = pd.DataFrame({'a': list(np.random.rand(8)) + [123456, np.nan],
'b': [0,1,2,3,np.nan,5,6,np.nan,8,9],
'c': [np.nan] + list("qwertzuio"),
'd': [pd.to_datetime(_) for _ in range(10)],
'e': [pd.Timedelta(_) for _ in range(10)],
'f': [True] * 5 + [False] * 5,
'g': pd.Series(list("abcbabbcaa"), dtype="category")})
cols = df.select_dtypes('number').columns
df_sub = df.loc[:, cols]
lim = np.abs((df_sub - df_sub.mean()) / df_sub.std(ddof=0)) < 3
lim = np.logical_and(df_sub < df_sub.quantile(0.99, numeric_only=False),
df_sub > df_sub.quantile(0.01, numeric_only=False))
iqr = df_sub.quantile(0.75, numeric_only=False) - df_sub.quantile(0.25, numeric_only=False)
lim = np.abs((df_sub - df_sub.median()) / iqr) < 2.22
df.loc[:, cols] = df_sub.where(lim, np.nan)
删除包含至少一个NaN值的所有行:
df.dropna(subset=cols, inplace=True)
df.dropna(inplace=True)
使用 pandas 1.3 函数: