这里有一个物理实验的结果,可以用直方图[i, amount_of(i)]表示。我认为这个结果可以用4-6个高斯函数的混合来估计。
是否有Python包能够将直方图作为输入,并返回混合分布中每个高斯分布的均值和方差?
例如原始数据如下:
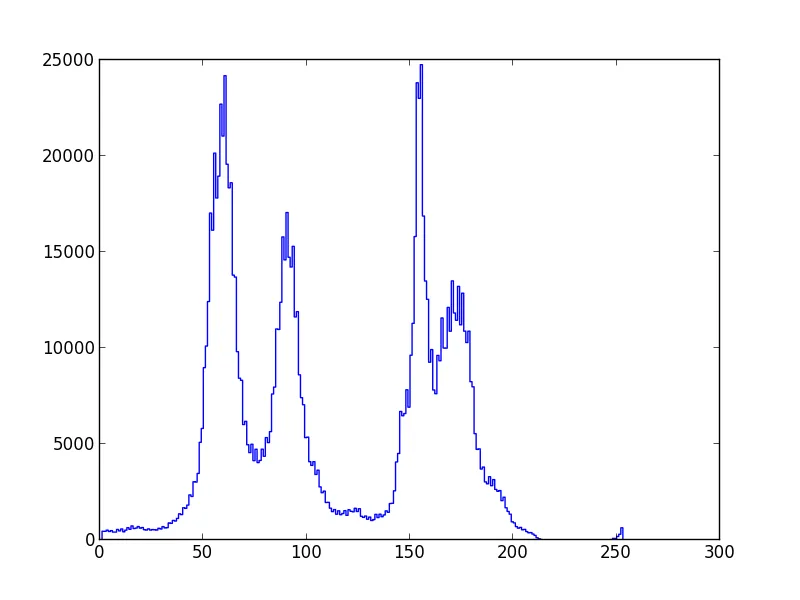
这里有一个物理实验的结果,可以用直方图[i, amount_of(i)]表示。我认为这个结果可以用4-6个高斯函数的混合来估计。
是否有Python包能够将直方图作为输入,并返回混合分布中每个高斯分布的均值和方差?
例如原始数据如下:
这是一个高斯混合模型,可以使用最大期望算法来估计(基本上,它同时找到分布的中心和均值以及它们如何混合)。
这在PyMix包中实现。下面我生成一个正态分布的混合示例,并使用PyMix对其进行混合模型拟合,包括确定您感兴趣的子群体的大小:
# requires numpy and PyMix (matplotlib is just for making a histogram)
import random
import numpy as np
from matplotlib import pyplot as plt
import mixture
random.seed(010713) # to make it reproducible
# create a mixture of normals:
# 1000 from N(0, 1)
# 2000 from N(6, 2)
mix = np.concatenate([np.random.normal(0, 1, [1000]),
np.random.normal(6, 2, [2000])])
# histogram:
plt.hist(mix, bins=20)
plt.savefig("mixture.pdf")
以上代码只是生成和绘制混合结果,结果如下图所示:
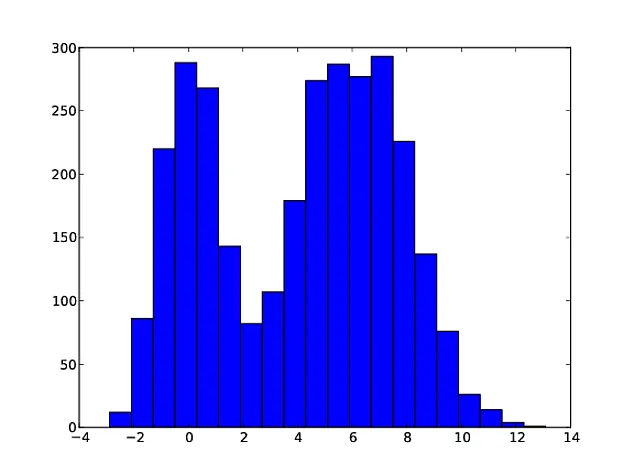
现在要使用PyMix来确定百分比:
data = mixture.DataSet()
data.fromArray(mix)
# start them off with something arbitrary (probably based on a guess from the figure)
n1 = mixture.NormalDistribution(-1,1)
n2 = mixture.NormalDistribution(1,1)
m = mixture.MixtureModel(2,[0.5,0.5], [n1,n2])
# perform expectation maximization
m.EM(data, 40, .1)
print m
这个的输出模型是:
G = 2
p = 1
pi =[ 0.33307859 0.66692141]
compFix = [0, 0]
Component 0:
ProductDist:
Normal: [0.0360178848449, 1.03018725918]
Component 1:
ProductDist:
Normal: [5.86848468319, 2.0158608802]
注意它正确地发现了两个正态分布 (一个 N(0, 1) 和一个 N(6, 2), 大约), 它还估计了pi,这是两个分布中的比例 (你在评论中提到这是你最感兴趣的)。我们在第一个分布中有1000个样本,在第二个分布中有2000个样本,它几乎完全正确地得出了比例: [0.33307859 0.66692141]。如果您想直接获得此值,请运行 m.pi。
一些注意事项:
[(1.4, 2), (2.6, 3)] 转换成 [1.4, 1.4, 2.6, 2.6, 2.6])