如何使用Python创建QQ图?
假定您有一组大量的测量数据并使用某个绘图函数将XY值作为输入。该函数应该将测量的分位数与某个分布(正态、均匀分布等)对应的分位数进行绘制。
生成的图形可以让我们评估测量结果是否符合所假设的分布。
http://en.wikipedia.org/wiki/Quantile-quantile_plot
R和Matlab都提供了用于此目的的现成函数,但我想知道在Python中实现该功能的最干净的方法是什么。
如何使用Python创建QQ图?
假定您有一组大量的测量数据并使用某个绘图函数将XY值作为输入。该函数应该将测量的分位数与某个分布(正态、均匀分布等)对应的分位数进行绘制。
生成的图形可以让我们评估测量结果是否符合所假设的分布。
http://en.wikipedia.org/wiki/Quantile-quantile_plot
R和Matlab都提供了用于此目的的现成函数,但我想知道在Python中实现该功能的最干净的方法是什么。
更新:正如网友所指出的,本回答是不正确的。Probplot与分位数-分位数图不同。在解释或传达分布关系之前,请查看这些评论和其他答案。
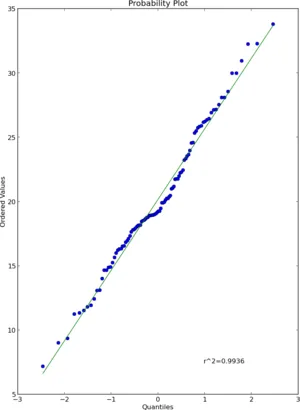
我认为scipy.stats.probplot可以满足你的需求。有关更多详细信息,请参见文档。
import numpy as np
import pylab
import scipy.stats as stats
measurements = np.random.normal(loc = 20, scale = 5, size=100)
stats.probplot(measurements, dist="norm", plot=pylab)
pylab.show()
结果
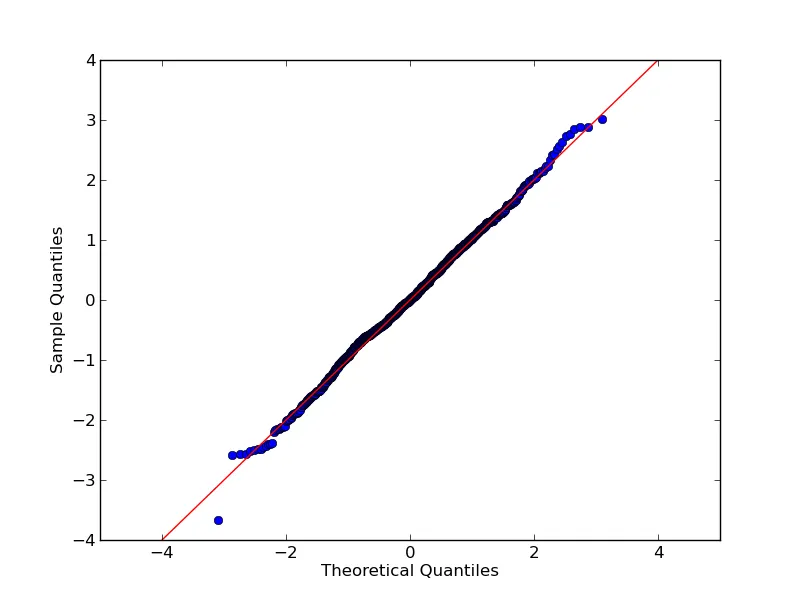
使用 statsmodels.api 的 qqplot 是另一种选择:
非常基本的示例:
import numpy as np
import statsmodels.api as sm
import pylab
test = np.random.normal(0,1, 1000)
sm.qqplot(test, line='45')
pylab.show()
结果:
文档和更多示例可在此处查看。
scipy 分离到 statsmodels 中的。 - SARosestatsmodels 将是一个不错的选择。 - Ken Tnp.random中的任何其他分布替换np.random.normal来将数据与其他分布进行比较。#!/bin/python
import numpy as np
measurements = np.random.normal(loc = 20, scale = 5, size=100000)
def qq_plot(data, sample_size):
qq = np.ones([sample_size, 2])
np.random.shuffle(data)
qq[:, 0] = np.sort(data[0:sample_size])
qq[:, 1] = np.sort(np.random.normal(size = sample_size))
return qq
print qq_plot(measurements, 1000)
probplot生成一个概率图,不应与Q-Q或P-P图混淆。Statsmodels具有更广泛的功能类型,请参见statsmodels.api.ProbPlot。”scipy.stats.probplot,您会发现它确实将数据集与理论分布进行比较。而另一方面,Q-Q图则将两个数据集(样本)进行比较。qqnorm、qqplot和qqline。来自R帮助文档(版本3.6.3):
qqnorm是一个通用函数,其默认方法生成 y 值的正态 QQ 图。qqline在“理论上”的分位数-分位数图中添加一条线,默认情况下为正常值,并通过 probs 分位数(默认情况下为第一和第三四分位数)。
qqplot生成两个数据集的 QQ 图。
简而言之,R 的 qqnorm 提供了与 scipy.stats.probplot 相同的功能,其默认设置为 dist=norm。但是,他们称之为 qqnorm 并且它应该“生成正常 QQ 图”,这可能会让用户感到困惑。
最后,警告一句。这些图不能替代适当的统计测试,仅应用于说明目的。
from bokeh.plotting import figure, show
from scipy.stats import probplot
# pd_series is the series you want to plot
series1 = probplot(pd_series, dist="norm")
p1 = figure(title="Normal QQ-Plot", background_fill_color="#E8DDCB")
p1.scatter(series1[0][0],series1[0][1], fill_color="red")
show(p1)
import numpy as np
import pylab
import scipy.stats as stats
measurements = np.random.normal(loc = 20, scale = 5, size=100)
stats.probplot(measurements, dist="norm", plot=pylab)
pylab.show()
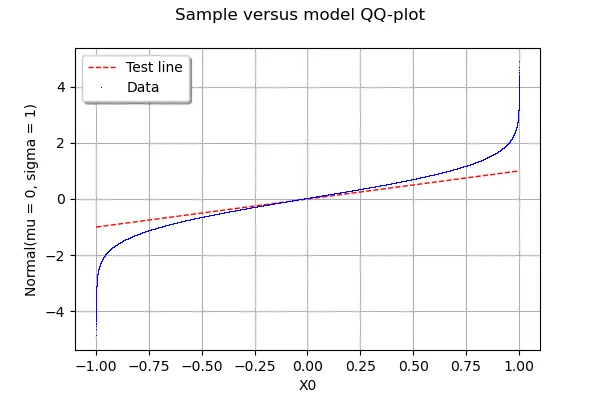
你的样本有多大?这里有另一种选项,可以使用OpenTURNS库测试数据是否符合任何分布。在下面的示例中,我从均匀分布中生成了一个包含100万个数字的样本x,并将其与正态分布进行了测试。
如果你将数据重新整形为x=[[x1],[x2],..,[xn]],就可以替换x。
import openturns as ot
x = ot.Uniform().getSample(1000000)
g = ot.VisualTest.DrawQQplot(x, ot.Normal())
g
 如果您正在编写脚本,您可以更加规范地执行它。
如果您正在编写脚本,您可以更加规范地执行它。from openturns.viewer import View`
import matplotlib.pyplot as plt
View(g)
plt.show()
probplot吗?http://docs.scipy.org/doc/scipy/reference/generated/scipy.stats.probplot.html - Geoff