这里是基于NumPy数组的方法,使用切片,让我们可以使用对输入数组的视图以提高效率 -
def comp_prev(a):
return np.concatenate(([False],a[1:] == a[:-1]))
df['match'] = comp_prev(df.col1.values)
样例运行 -
In [48]: df['match'] = comp_prev(df.col1.values)
In [49]: df
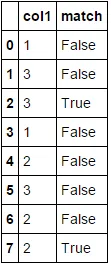
Out[49]:
col1 match
0 1 False
1 3 False
2 3 True
3 1 False
4 2 False
5 3 False
6 2 False
7 2 True
运行时测试 -
In [56]: data={'col1':[1,3,3,1,2,3,2,2]}
...: df0=pd.DataFrame(data,columns=['col1'])
...:
In [57]: df = pd.concat([df0]*10000).reset_index(drop=True)
In [58]: %timeit df['match'] = df.col1 == df.col1.shift()
1000 loops, best of 3: 1.53 ms per loop
In [59]: df = pd.concat([df0]*10000).reset_index(drop=True)
In [60]: %timeit df['match'] = df.col1.eq(df.col1.shift())
1000 loops, best of 3: 1.49 ms per loop
In [61]: df = pd.concat([df0]*10000).reset_index(drop=True)
In [64]: %timeit df['match'] = df['col1'].diff().eq(0)
1000 loops, best of 3: 1.02 ms per loop
In [65]: df = pd.concat([df0]*10000).reset_index(drop=True)
In [66]: %timeit df['match'] = np.ediff1d(df['col1'].values, to_begin=np.NaN) == 0
1000 loops, best of 3: 1.52 ms per loop
In [67]: df = pd.concat([df0]*10000).reset_index(drop=True)
In [68]: %timeit df['match'] = comp_prev(df.col1.values)
1000 loops, best of 3: 376 µs per loop
eq,ne,lt等比==,!=,>更快。在更大的df中,您的计时是多少? - jezrael