你可以使用
DataFrame 构造函数:
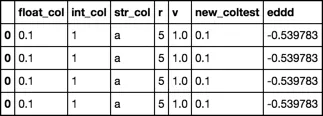
N = 10
df =pd.DataFrame(newsampledata.values.tolist(),index=np.arange(N),columns=sampledata.columns)
print (df)
float_col int_col str_col r v new_coltest eddd
0 0.1 1 a 5 1.0 0.1 -0.539783
1 0.1 1 a 5 1.0 0.1 -0.539783
2 0.1 1 a 5 1.0 0.1 -0.539783
3 0.1 1 a 5 1.0 0.1 -0.539783
4 0.1 1 a 5 1.0 0.1 -0.539783
5 0.1 1 a 5 1.0 0.1 -0.539783
6 0.1 1 a 5 1.0 0.1 -0.539783
7 0.1 1 a 5 1.0 0.1 -0.539783
8 0.1 1 a 5 1.0 0.1 -0.539783
9 0.1 1 a 5 1.0 0.1 -0.539783
print (df.dtypes)
float_col float64
int_col int64
str_col object
r int64
v float64
new_coltest float64
eddd float64
dtype: object
时间:
在大型的DataFrame构造方法中,小型的DataFrame使用sample和reindex方法更快。
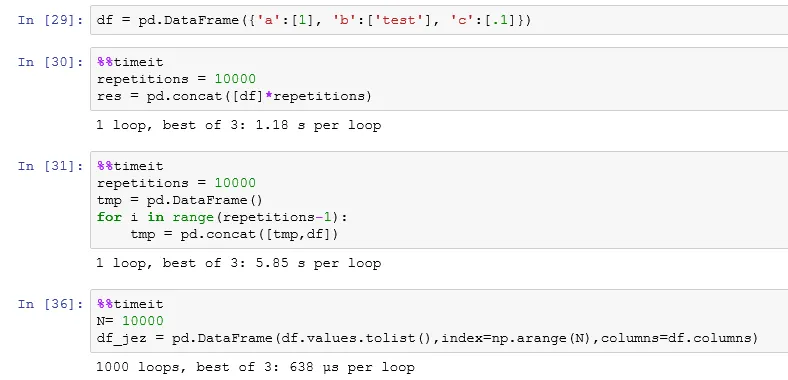
N = 1000
In [88]: %timeit (pd.DataFrame(newsampledata.values.tolist(), index=np.arange(N), columns=sampledata.columns))
1000 loops, best of 3: 745 µs per loop
In [89]: %timeit (newsampledata.sample(N, replace=True).reset_index(drop=True))
The slowest run took 4.88 times longer than the fastest. This could mean that an intermediate result is being cached.
1000 loops, best of 3: 470 µs per loop
In [90]: %timeit (newsampledata.reindex(newsampledata.index.repeat(N)).reset_index(drop=True))
1000 loops, best of 3: 476 µs per loop
N = 10000
In [92]: %timeit (pd.DataFrame(newsampledata.values.tolist(), index=np.arange(N), columns=sampledata.columns))
1000 loops, best of 3: 946 µs per loop
In [93]: %timeit (newsampledata.sample(N, replace=True).reset_index(drop=True))
1000 loops, best of 3: 775 µs per loop
In [94]: %timeit (newsampledata.reindex(newsampledata.index.repeat(N)).reset_index(drop=True))
1000 loops, best of 3: 827 µs per loop
N = 100000
In [97]: %timeit (pd.DataFrame(newsampledata.values.tolist(), index=np.arange(N), columns=sampledata.columns))
The slowest run took 12.98 times longer than the fastest. This could mean that an intermediate result is being cached.
100 loops, best of 3: 6.93 ms per loop
In [98]: %timeit (newsampledata.sample(N, replace=True).reset_index(drop=True))
100 loops, best of 3: 7.07 ms per loop
In [99]: %timeit (newsampledata.reindex(newsampledata.index.repeat(N)).reset_index(drop=True))
100 loops, best of 3: 7.87 ms per loop
N = 10000000
In [83]: %timeit (pd.DataFrame(newsampledata.values.tolist(), index=np.arange(N), columns=sampledata.columns))
1 loop, best of 3: 589 ms per loop
In [84]: %timeit (newsampledata.sample(N, replace=True).reset_index(drop=True))
1 loop, best of 3: 757 ms per loop
In [85]: %timeit (newsampledata.reindex(newsampledata.index.repeat(N)).reset_index(drop=True))
1 loop, best of 3: 731 ms per loop
In [108]: %timeit numpy_tile(newsampledata,10000000)1 loop, best of 3: 7.42 s per loop- jezrael