据我了解,目前sklearn没有针对最佳子集的“暴力”/穷举特征搜索功能。然而,有各种类:
现在,对于这个问题的流水线处理可能会有些棘手。当您将类/方法堆叠在一个管道中并调用.fit()时,直到最后一个方法,所有方法都必须公开.transform()。如果一个方法公开了.transform(),那么这个.transform()将被用作下一步的输入等等。在最后一步中,您可以将任何有效的模型作为最终对象,但是之前的所有步骤都必须公开.transform()以便链接到另一个步骤。因此,根据您选择的特征选择方法,您的代码将有所不同。请参见下文
巴勃罗·毕加索曾经说过,“好的艺术家会借鉴,伟大的艺术家会窃取。”... 因此,在这个很棒的回答
https://dev59.com/ZZ_ha4cB1Zd3GeqPuzLW#42271829的指引下,我们来借鉴、修正并进一步扩展。
导入
import itertools
from itertools import combinations
import pandas as pd
from tqdm import tqdm
from sklearn.pipeline import Pipeline
from sklearn.datasets import load_diabetes
from sklearn.preprocessing import StandardScaler
from sklearn.feature_selection import RFE, SelectKBest
from sklearn.model_selection import GridSearchCV, KFold
from sklearn.linear_model import PoissonRegressor
from IPython.core.interactiveshell import InteractiveShell
InteractiveShell.ast_node_interactivity = "all"
数据
X, y = load_diabetes(as_frame=True, return_X_y=True)
补充函数
def make_param_grids(steps, param_grids):
final_params=[]
for estimator_names in itertools.product(*steps.values()):
current_grid = {}
for step_name, estimator_name in zip(steps.keys(), estimator_names):
for param, value in param_grids.get(estimator_name).items():
if param == 'object':
current_grid[step_name]=[value]
else:
current_grid[step_name+'__'+param]=value
final_params.append(current_grid)
return final_params
#1 使用RFE特征选择类的示例
(也称特征选择类不返回转换结果,但是是包装类型)
pipeline_steps = {'transform':['ss'],
'classifier':['rf']}
all_param_grids = {'ss':{'object':StandardScaler(),
'with_mean':[True,False]
},
'rf':{'object':RFE(estimator=PoissonRegressor(),
step=1,
verbose=0),
'n_features_to_select':[1,2,3,4,5,6,7,8,9,10],
'estimator__fit_intercept':[True,False],
'estimator__alpha':[0.1,0.5,0.7,1]
}
}
param_grids_list = make_param_grids(pipeline_steps, all_param_grids)
param_grids_list

pipe = Pipeline(steps=[('transform',StandardScaler()),
('classifier',RFE(estimator=PoissonRegressor()))])
pipe

gs_en_cv = GridSearchCV(pipe,
param_grid=param_grids_list,
cv=KFold(n_splits=3,
shuffle = True,
random_state=123),
scoring = 'neg_root_mean_squared_error',
return_train_score=True,
verbose = 1)
gs_en_cv.fit(X,y)
f"``````````````````````````````````````````````````````````````````````````````````````"
f"best score is {gs_en_cv.best_score_}"
f"``````````````````````````````````````````````````````````````````````````````````````"
f"best params are"
gs_en_cv.best_params_
f"good luck"

#2 使用KBest特征选择类的示例
(一个展示特征选择.expose .transform()方法的示例)
pipeline_steps = {'transform':['ss'],
'select':['kbest'],
'classifier':['pr']}
all_param_grids = {'ss':{'object':StandardScaler(),
'with_mean':[True,False]
},
'kbest': {'object': SelectKBest(),
'k' : [1,2,3,4,5,6,7,8,9,10]
},
'pr':{'object':PoissonRegressor(verbose=2),
'alpha':[0.1,0.25,0.5,0.75,1],
'fit_intercept':[True,False],
}
}
param_grids_list = make_param_grids(pipeline_steps, all_param_grids)
param_grids_list

pipe = Pipeline(steps=[('transform',StandardScaler()),
( 'select', SelectKBest()),
('classifier',PoissonRegressor())])
pipe

gs_en_cv = GridSearchCV(pipe,
param_grid=param_grids_list,
cv=KFold(n_splits=3,
shuffle = True,
random_state=123),
scoring = 'neg_root_mean_squared_error',
return_train_score=True,
verbose = 1)
gs_en_cv.fit(X,y)
f"``````````````````````````````````````````````````````````````````````````````````````"
f"best score is {gs_en_cv.best_score_}"
f"``````````````````````````````````````````````````````````````````````````````````````"
f"best params are"
gs_en_cv.best_params_
f"good luck"

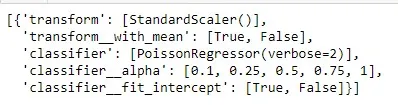
#3 暴力破解/使用管道循环遍历所有可能的组合
pipeline_steps = {'transform':['ss'],
'classifier':['pr']}
all_param_grids = {'ss':{'object':StandardScaler(),
'with_mean':[True,False]
},
'pr':{'object':PoissonRegressor(verbose=2),
'alpha':[0.1,0.25,0.5,0.75,1],
'fit_intercept':[True,False],
}
}
param_grids_list = make_param_grids(pipeline_steps, all_param_grids)
param_grids_list
pipe = Pipeline(steps=[('transform',StandardScaler()),
('classifier',PoissonRegressor())])
pipe

feature_combo = []
score = []
params = []
stuff = list(X.columns)
for L in tqdm(range(1, len(stuff)+1)):
for subset in itertools.combinations(stuff, L):
gs_en_cv = GridSearchCV(pipe,
param_grid=param_grids_list,
cv=KFold(n_splits=3,
shuffle = True,
random_state=123),
scoring = 'neg_root_mean_squared_error',
return_train_score=True,
verbose = 0)
fitted = gs_en_cv.fit(X[list(subset)],y)
score.append(fitted.best_score_)
params.append(fitted.best_params_)
feature_combo.append(list(subset))

df = pd.DataFrame({'feature_combo':feature_combo,
'score':score,
'params':params})
df.sort_values(by='score', ascending=False,inplace=True)
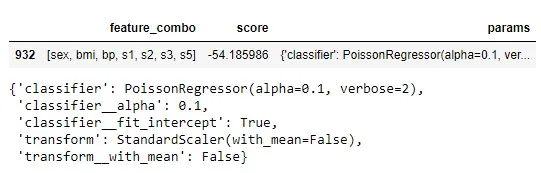
df.head(1)
df.head(1).params.iloc[0]
PS
对于交互作用(我猜你指的是通过组合原始特征来创建新特征?),我会在.fit()之前直接创建这些特征交互,并将它们包含在其中,因为否则你怎么知道例如你是否获得了最佳交互特征,因为你是在选择子集之后进行交互的之后?为什么不从一开始就相互作用,让gridCV的特征选择部分告诉你最好的方法呢?
ALLhttps://scikit-learn.org/stable/modules/feature_selection.html 类,但很容易将我的代码扩展到所有类。PoissonRegressor()出现两次,因为一次用于MODEL,另一次在RFE内部使用,需要估计器作为其参数之一。在RFE中包括PoissonRergressor和DecisionTreeRegressor意味着CV将把它们视为要尝试的超参数。您也可以在RFE中添加其他模型,它们将在交叉验证中尝试。我只放了2个模型,以便您了解如何利用它。 - Yev Guyduy