(previously posted here, to the wrong sub, with not enough info, which was closed, I edited, the edits seem to have been deleted, & the post consigned to purgatory, so apologies for re-posting, I don't know whether the previous post can/should be resurrected)
在R中,我运行了一些提升回归树,也称为广义提升模型,使用了dismo和gbm。以下是一个可重现的示例,使人们能够到达我当前的位置:
人们似乎在网络上已经提出了类似的问题,但似乎没有成功。BRT模型通常被描述为“黑匣子”,因此可能普遍的观点是不应该/不能/不必要去探究它们并显示它们的内部过程。
如果有人对BRT /
在R中,我运行了一些提升回归树,也称为广义提升模型,使用了dismo和gbm。以下是一个可重现的示例,使人们能够到达我当前的位置:
library(dismo); data(Anguilla_train)
angaus.tc5.lr01 <- gbm.step(data=Anguilla_train, gbm.x = 3:13, gbm.y = 2, family = "bernoulli", tree.complexity = 5, learning.rate = 0.01, bag.fraction = 0.5)
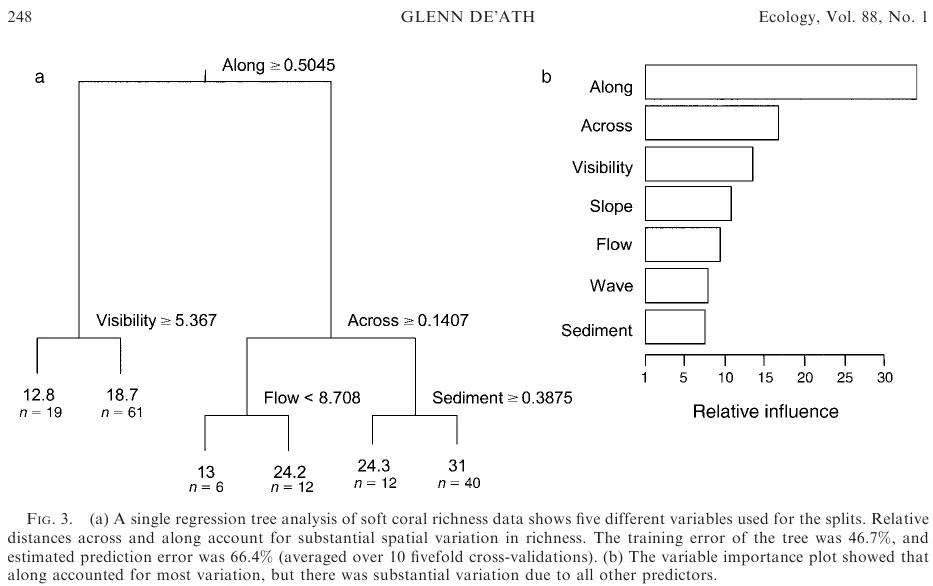
(来自这里). 这将使您拥有 gbm 模型对象 "angaus.tc5.lr01"。 我想生成分裂(折叠)的树状图,即绘制树,如 De'ath 2007 所示(见图片,左窗格)。但是:De'ath 的绘图是单个回归树,而不是提升回归树,后者是可能运行数千个树的平均值,每个树都使用从数据集中随机抽取的不同数据集。
用户ckluss友好地建议使用rpart,但是需要由rpart生成模型,因此对于由gbm.step生成的BRTs / GBMs无法使用。 这也适用于来自rpart.plot的prp。
gbm中的pretty.gbm.tree提取了所选任意一棵树的信息矩阵(尝试使用pretty.gbm.tree(angaus.tc5.lr01, i.tree=1)来获取第一棵),因此我想知道这是否是成功的可行路径?例如,编写一些脚本,使用所有可用的树创建一个平均树矩阵,然后将其转换为树状对象,可能使用here中的一些方法。人们似乎在网络上已经提出了类似的问题,但似乎没有成功。BRT模型通常被描述为“黑匣子”,因此可能普遍的观点是不应该/不能/不必要去探究它们并显示它们的内部过程。
如果有人对BRT /
gbm了解足够多,并有任何想法,他们将不胜感激。谢谢。