编辑:我改进了测试以提供更准确的时间。我还优化了展开版本,现在比我最初的版本好得多,但是随着大小的增加,矩阵乘法速度仍然更快。
编辑2:为了确保JIT编译器在展开函数上工作,我修改了代码以将生成的函数写为M文件。另外,现在可以通过传递TIMEIT函数句柄来公平地比较两种方法的性能:timeit(@myfunc)
我不相信你的方法比矩阵乘法更快,对于适当大小的数据。因此我们来比较这两种方法。
我使用符号数学工具箱来获取方程式
x'*A*x 的“展开”形式(手工计算一个20x20的矩阵和一个20x1的向量很费劲!)。
function f = buildUnrolledFunction(N)
fname = sprintf('f%d',N);
if exist([fname '.m'], 'file')
f = str2func(fname);
return
end
x = sym('x', [N 1]);
A = sym('A', [N N]);
s = ccode(expand(x.'*A*x));
s = regexprep(regexprep(s, '^.*=\s+', ''), ';$', '');
s = regexprep(regexprep(s, 'x(\d+)', 'x($1)'), 'A(\d+)_(\d+)', ...
'A(${ int2str(sub2ind([N N],str2num($1),str2num($2))) })');
fid = fopen([fname '.m'], 'wt');
fprintf(fid, 'function v = %s(A,x)\nv = %s;\nend\n', fname, s);
fclose(fid);
rehash
clear(fname)
f = str2func(fname);
end
我试图通过避免使用指数运算(我们更喜欢 x*x 而不是 x^2)来优化生成的函数。我还将下标转换为线性索引(A(9) 而不是 A(3,3))。因此,当 n=3 时,我们得到了与您相同的方程:
>> s
s =
A(1)*(x(1)*x(1)) + A(5)*(x(2)*x(2)) + A(9)*(x(3)*x(3)) +
A(4)*x(1)*x(2) + A(7)*x(1)*x(3) + A(2)*x(1)*x(2) +
A(8)*x(2)*x(3) + A(3)*x(1)*x(3) + A(6)*x(2)*x(3)
考虑到上述构建M函数的方法,我们现在对不同大小的问题进行评估,并将其与矩阵乘法形式进行比较(我将其放在单独的函数中以考虑函数调用开销)。为了获得更准确的计时,我使用TIMEIT函数而不是tic/toc。此外,为了公平比较,每种方法都作为一个M文件函数实现,并将所有所需变量作为输入参数传递。
function results = testMatrixMultVsUnrolled()
N_vec = 2:50;
results = zeros(numel(N_vec),3);
for ii = 1:numel(N_vec);
N = N_vec(ii);
x = rand(N,1); A = rand(N,N);
f = @matMult;
results(ii,1) = timeit(@() feval(f, A,x));
f = buildUnrolledFunction(N);
results(ii,2) = timeit(@() feval(f, A,x));
results(ii,3) = norm(matMult(A,x) - f(A,x));
end
fprintf('N = %2d: mtimes = %.6f ms, unroll = %.6f ms [error = %g]\n', ...
[N_vec(:) results(:,1:2)*1e3 results(:,3)]')
plot(N_vec, results(:,1:2)*1e3, 'LineWidth',2)
xlabel('size (N)'), ylabel('timing [msec]'), grid on
legend({'mtimes','unrolled'})
title('Matrix multiplication: $$x^\mathsf{T}Ax$$', ...
'Interpreter','latex', 'FontSize',14)
end
function v = matMult(A,x)
v = x.' * A * x;
end
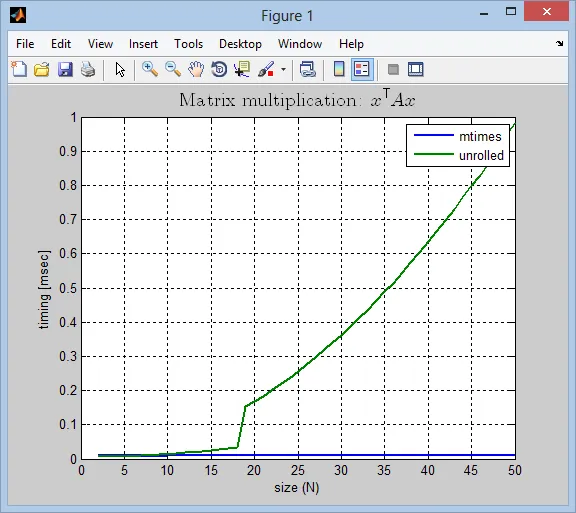
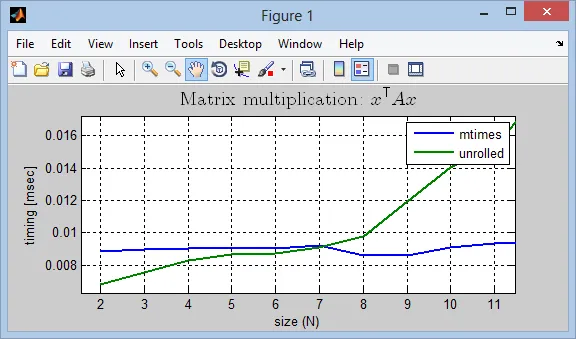
结果如下:
N = 2: mtimes = 0.008816 ms, unroll = 0.006793 ms [error = 0]
N = 3: mtimes = 0.008957 ms, unroll = 0.007554 ms [error = 0]
N = 4: mtimes = 0.009025 ms, unroll = 0.008261 ms [error = 4.44089e-16]
N = 5: mtimes = 0.009075 ms, unroll = 0.008658 ms [error = 0]
N = 6: mtimes = 0.009003 ms, unroll = 0.008689 ms [error = 8.88178e-16]
N = 7: mtimes = 0.009234 ms, unroll = 0.009087 ms [error = 1.77636e-15]
N = 8: mtimes = 0.008575 ms, unroll = 0.009744 ms [error = 8.88178e-16]
N = 9: mtimes = 0.008601 ms, unroll = 0.011948 ms [error = 0]
N = 10: mtimes = 0.009077 ms, unroll = 0.014052 ms [error = 0]
N = 11: mtimes = 0.009339 ms, unroll = 0.015358 ms [error = 3.55271e-15]
N = 12: mtimes = 0.009271 ms, unroll = 0.018494 ms [error = 3.55271e-15]
N = 13: mtimes = 0.009166 ms, unroll = 0.020238 ms [error = 0]
N = 14: mtimes = 0.009204 ms, unroll = 0.023326 ms [error = 7.10543e-15]
N = 15: mtimes = 0.009396 ms, unroll = 0.024767 ms [error = 3.55271e-15]
N = 16: mtimes = 0.009193 ms, unroll = 0.027294 ms [error = 2.4869e-14]
N = 17: mtimes = 0.009182 ms, unroll = 0.029698 ms [error = 2.13163e-14]
N = 18: mtimes = 0.009330 ms, unroll = 0.033295 ms [error = 7.10543e-15]
N = 19: mtimes = 0.009411 ms, unroll = 0.152308 ms [error = 7.10543e-15]
N = 20: mtimes = 0.009366 ms, unroll = 0.167336 ms [error = 7.10543e-15]
N = 21: mtimes = 0.009335 ms, unroll = 0.183371 ms [error = 0]
N = 22: mtimes = 0.009349 ms, unroll = 0.200859 ms [error = 7.10543e-14]
N = 23: mtimes = 0.009411 ms, unroll = 0.218477 ms [error = 8.52651e-14]
N = 24: mtimes = 0.009307 ms, unroll = 0.235668 ms [error = 4.26326e-14]
N = 25: mtimes = 0.009425 ms, unroll = 0.256491 ms [error = 1.13687e-13]
N = 26: mtimes = 0.009392 ms, unroll = 0.274879 ms [error = 7.10543e-15]
N = 27: mtimes = 0.009515 ms, unroll = 0.296795 ms [error = 2.84217e-14]
N = 28: mtimes = 0.009567 ms, unroll = 0.319032 ms [error = 5.68434e-14]
N = 29: mtimes = 0.009548 ms, unroll = 0.339517 ms [error = 3.12639e-13]
N = 30: mtimes = 0.009617 ms, unroll = 0.361897 ms [error = 1.7053e-13]
N = 31: mtimes = 0.009672 ms, unroll = 0.387270 ms [error = 0]
N = 32: mtimes = 0.009629 ms, unroll = 0.410932 ms [error = 1.42109e-13]
N = 33: mtimes = 0.009605 ms, unroll = 0.434452 ms [error = 1.42109e-13]
N = 34: mtimes = 0.009534 ms, unroll = 0.462961 ms [error = 0]
N = 35: mtimes = 0.009696 ms, unroll = 0.489474 ms [error = 5.68434e-14]
N = 36: mtimes = 0.009691 ms, unroll = 0.512198 ms [error = 8.52651e-14]
N = 37: mtimes = 0.009671 ms, unroll = 0.544485 ms [error = 5.68434e-14]
N = 38: mtimes = 0.009710 ms, unroll = 0.573564 ms [error = 8.52651e-14]
N = 39: mtimes = 0.009946 ms, unroll = 0.604567 ms [error = 3.41061e-13]
N = 40: mtimes = 0.009735 ms, unroll = 0.636640 ms [error = 3.12639e-13]
N = 41: mtimes = 0.009858 ms, unroll = 0.665719 ms [error = 5.40012e-13]
N = 42: mtimes = 0.009876 ms, unroll = 0.697364 ms [error = 0]
N = 43: mtimes = 0.009956 ms, unroll = 0.730506 ms [error = 2.55795e-13]
N = 44: mtimes = 0.009897 ms, unroll = 0.765358 ms [error = 4.26326e-13]
N = 45: mtimes = 0.009991 ms, unroll = 0.800424 ms [error = 0]
N = 46: mtimes = 0.009956 ms, unroll = 0.829717 ms [error = 2.27374e-13]
N = 47: mtimes = 0.010210 ms, unroll = 0.865424 ms [error = 2.84217e-13]
N = 48: mtimes = 0.010022 ms, unroll = 0.907974 ms [error = 3.97904e-13]
N = 49: mtimes = 0.010098 ms, unroll = 0.944536 ms [error = 5.68434e-13]
N = 50: mtimes = 0.010153 ms, unroll = 0.984486 ms [error = 4.54747e-13]
在小尺寸下,这两种方法表现相似。虽然对于
N<7,扩展版击败了
mtimes,但差别几乎不显著。一旦我们超过微小的尺寸,矩阵乘法比扩展版快几个数量级。
这并不令人惊讶;仅有
N=20 时,
formula 就变得非常长,并涉及添加 400 项。由于 MATLAB 语言是解释型的,我怀疑这不是很有效率的。
现在我同意调用外部函数与直接内嵌代码相比存在一定的开销,但这种方法实际有多实用呢?即使是小尺寸如
N=20,生成的行也超过7000个字符!我还注意到MATLAB编辑器因为长行而变得迟缓 :)
此外,在大约
N>10之后,优势很快消失。我进行了嵌入式代码/显式编写与矩阵乘法的比较,类似于@DennisJaheruddin所建议的。
结果:
N=3:
Elapsed time is 0.062295 seconds. % unroll
Elapsed time is 1.117962 seconds. % mtimes
N=12:
Elapsed time is 1.024837 seconds. % unroll
Elapsed time is 1.126147 seconds. % mtimes
N=19:
Elapsed time is 140.915138 seconds. % unroll
Elapsed time is 1.305382 seconds. % mtimes
...对于未展开版本而言,情况只会变得更糟。正如我之前所说,MATLAB是解释性语言,因此在处理如此庞大的文件时,代码解析的成本开始显现。
在我看来,在执行一百万次迭代后,我们最多只能节省1秒钟的时间,我认为这并不能证明所有麻烦和hack的必要性,相比之下,使用更易读且简洁的v=x'*A*x要好得多。因此,也许在代码中有其他地方可以改进,而不是专注于已经优化的操作,例如矩阵乘法。
矩阵乘法在MATLAB中非常 快速(这是MATLAB最擅长的!)。当您处理足够大的数据时(多线程开始运行),它真正发挥出色:
>> N=5000; x=rand(N,1); A=rand(N,N);
>> tic, for i=1e4, v=x.'*A*x; end, toc
Elapsed time is 0.021959 seconds.
v = x'*A*x,这样可以得到一个标量结果1x3 * 3x3 * 3x1 = 1x1。需要注意的是,如果 A 是对称矩阵,则这是二次方程的矩阵形式。 - AmrogpuArray。 - Will Faithfull