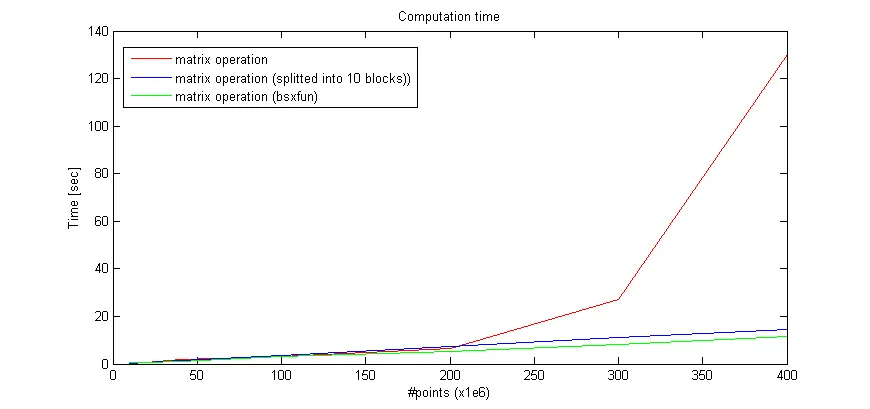
我需要在Matlab中操作大型三维非稀疏矩阵。使用纯向量化会导致计算时间很长。因此,我尝试将操作分成10个块,然后解析结果。当我看到以下图表时,我感到惊讶,发现纯向量化与数据大小不太相关。
我提供了两种方法的示例。
因此,我想知道是否还有其他方法可以使Matlab中的大矩阵操作更有效率。我知道这是一个非常广泛的问题,但我愿意冒险去问 :)
时间是:
我提供了两种方法的示例。
% Parameters:
M = 1e6; N = 50; L = 4; K = 10;
% Method 1: Pure vectorization
mat1 = randi(L,[M,N,L]);
mat2 = repmat(permute(1:L,[3 1 2]),M,N);
result1 = nnz(mat1>mat2)./(M+N+L);
% Method 2: Split computations
result2 = 0;
for ii=1:K
mat1 = randi(L,[M/K,N,L]);
mat2 = repmat(permute(1:L,[3 1 2]),M/K,N);
result2 = result2 + nnz(mat1>mat2);
end
result2 = result2/(M+N+L);
因此,我想知道是否还有其他方法可以使Matlab中的大矩阵操作更有效率。我知道这是一个非常广泛的问题,但我愿意冒险去问 :)
编辑:
使用@Shai的实现
% Method 3
mat3 = randi(L,[M,N,L]);
result3 = nnz(bsxfun( @gt, mat3, permute( 1:L, [3 1 2] ) ))./(M+N+L);
时间是:
bsxfun的文档中,我发现了单例扩展的解释:“每当A或B的一个维度是单例(等于一)时,bsxfun会在该维度上虚拟复制数组以匹配另一个数组”。我实际上不知道这个有用的功能。 - tashuhkabsxfun非常有用。请查看其标签wiki以获取更多信息。 - Shai