由于
MATLAB最初是为数值线性代数(矩阵操作)而开发的编程语言,具有专门开发的用于矩阵乘法的库。现在,
MATLAB还可以额外使用
GPU(图形处理器)。
如果我们看一下您的计算结果:
1024x1024 2048x2048 4096x4096
CUDA C (ms) 43.11 391.05 3407.99
C++ (ms) 6137.10 64369.29 551390.93
C# (ms) 10509.00 300684.00 2527250.00
Java (ms) 9149.90 92562.28 838357.94
MATLAB (ms) 75.01 423.10 3133.90
然后我们可以看到,不仅MATLAB在矩阵乘法方面非常快:
CUDA C(NVIDIA的编程语言)比MATLAB更好。CUDA C还有专门为矩阵乘法开发的库,并且它使用GPU。
MATLAB简史
克里夫·莫勒是新墨西哥大学计算机科学系主席,他在1970年代末开始开发MATLAB。他设计它是为了让他的学生能够使用
LINPACK(用于执行数值线性代数的软件库)和
EISPACK(用于数值计算线性代数的软件库),而不必学习Fortran。它很快传播到其他大学,并在应用数学界找到了强大的听众。1983年,工程师杰克·利特在莫勒访问斯坦福大学期间接触到了它。他意识到它的商业潜力,与莫勒和史蒂夫·班格特合作。他们用C重写了MATLAB,并于1984年创立了MathWorks以继续其发展。这些重写的库被称为JACKPAC。2000年,MATLAB被重写以使用一组更新的矩阵操作库,LAPACK(是用于数值线性代数的标准软件库)。
来源
CUDA C是什么?
CUDA C还使用了专门用于矩阵乘法的库,例如
OpenGL(开放图形库)。它还使用GPU和Direct3D(在MS Windows上)。
CUDA平台旨在与诸如C、C ++和Fortran等编程语言一起使用。这种可访问性使得并行编程专家更容易使用GPU资源,与之前的API(例如Direct3D和OpenGL)相比,这需要先进的图形编程技能。此外,CUDA支持编程框架,例如OpenACC和OpenCL。
CUDA处理流程示例:
1. 将数据从主内存复制到GPU内存
2. CPU启动GPU计算核心
3. GPU的CUDA核心并行执行核心
4. 将生成的数据从GPU内存复制到主内存
比较 CPU 和 GPU 的执行速度
我们进行了一个基准测试,测量在 Intel Xeon 处理器 X5650 上和使用 NVIDIA Tesla C2050 GPU 时,在网格大小为 64、128、512、1024 和 2048 时执行 50 个时间步骤所需的时间。
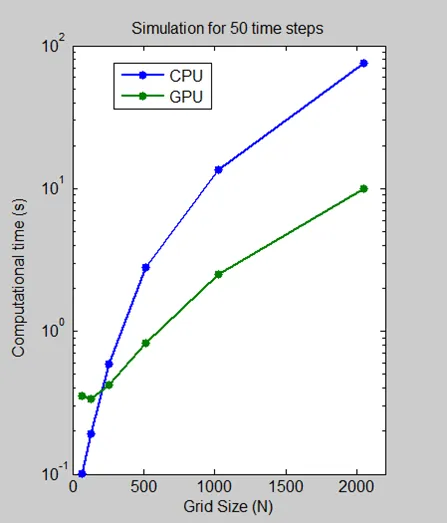
对于网格大小为 2048,该算法的计算时间从 CPU 上的一分钟以上降至 GPU 上的不到 10 秒,降低了 7.5 倍。对数刻度图显示,CPU 实际上在小网格大小时更快。然而,随着技术的发展和成熟,GPU 解决方案越来越能够处理较小的问题,这是我们预计会继续的趋势。
来源
来自 CUDA C 编程指南介绍:
由于市场对实时高清 3D 图形的需求不可满足,可编程图形处理器或 GPU 已经演变成高度并行、多线程、众核心的处理器,具有巨大的计算能力和非常高的内存带宽,如
图1 和
图2 所示。
图1。CPU 和 GPU 的浮点运算次数每秒。
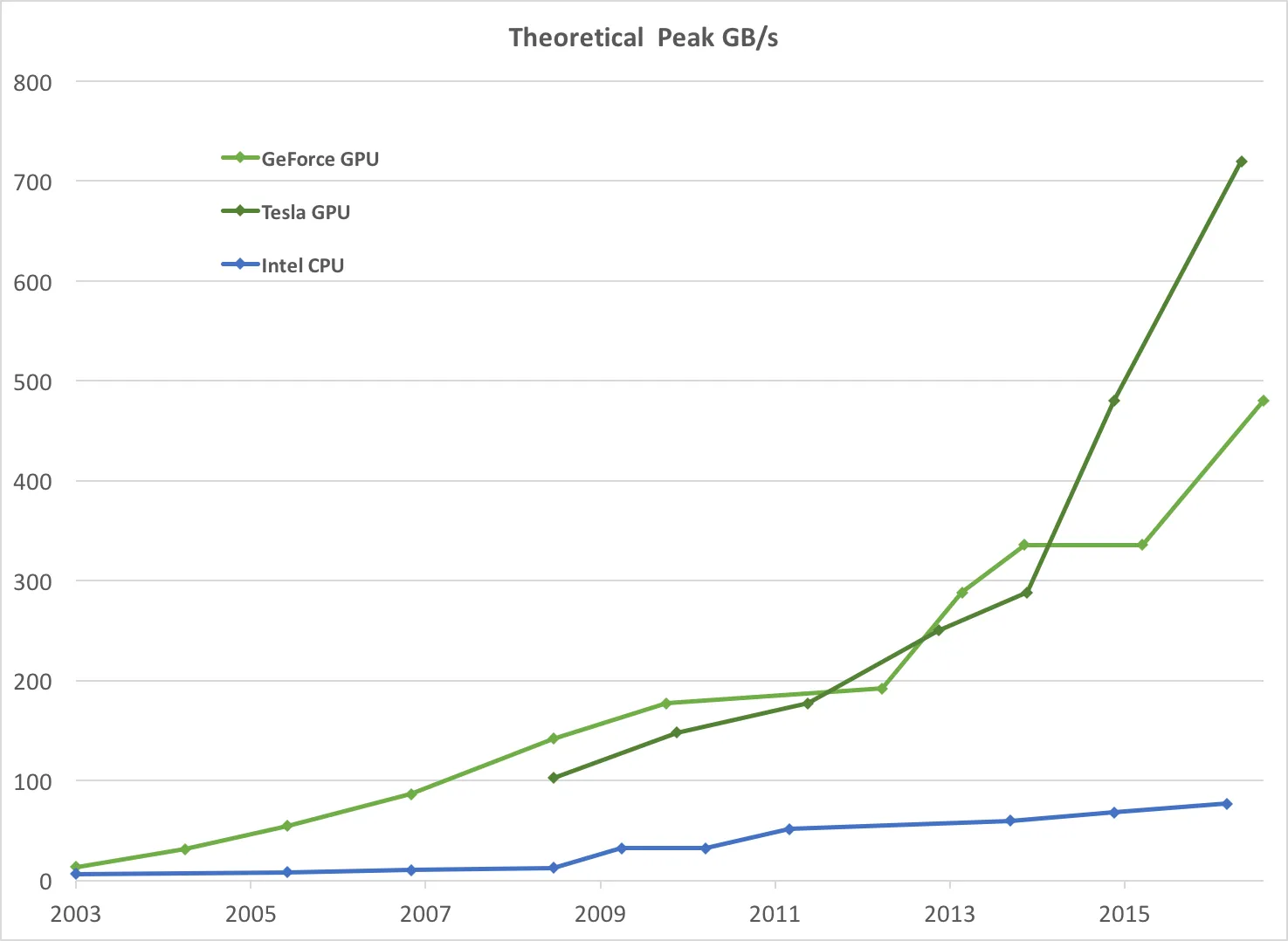
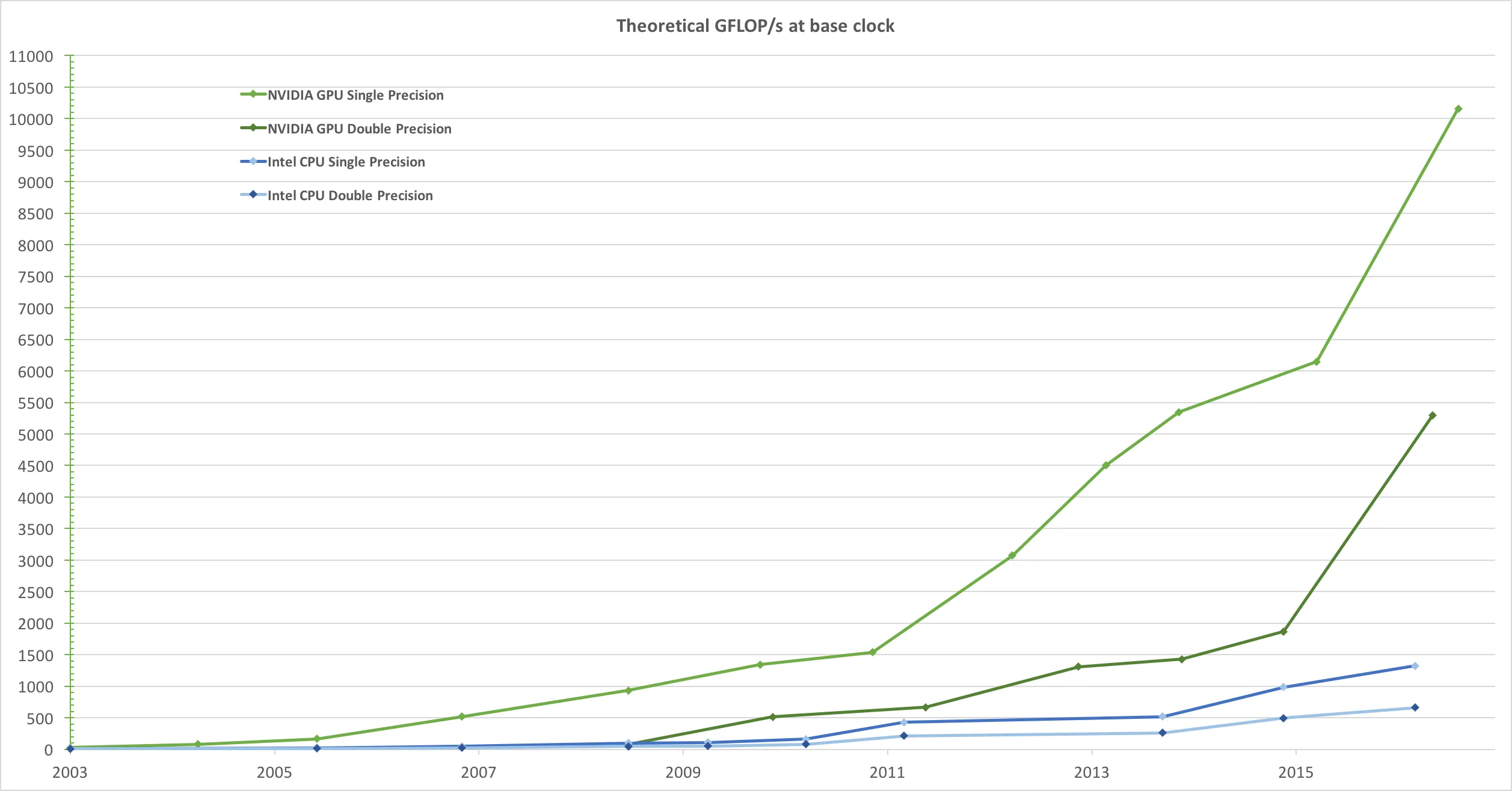 图2
图2。CPU 和 GPU 的内存带宽。
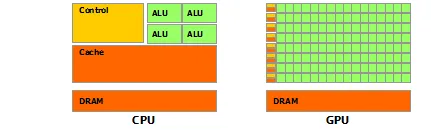
GPU 的浮点性能之所以比 CPU 更强,是因为 GPU 专门进行计算密集、高度并行的计算,这正是图形渲染所需的,因此设计中更多的晶体管用于数据处理而不是数据缓存和流量控制,如
图3 所示。
图3。GPU 更多晶体管用于数据处理。
更具体地说,GPU 特别适合解决可以表示为数据并行计算的问题,即同一程序在许多数据元素上并行执行,并具有高算术强度,即算术运算与内存操作的比值。由于每个数据元素都执行相同的程序,因此对复杂流控制的要求较低,并且由于它在许多数据元素上执行并具有高算术强度,因此可以通过计算来隐藏内存访问延迟,而不是使用大型数据缓存。
数据并行处理将数据元素映射到并行处理线程。许多处理大数据集的应用程序可以使用数据并行编程模型加速计算。在 3D 渲染中,大量像素和顶点被映射到并行线程。类似地,图像和媒体处理应用程序,如渲染图像后处理、视频编码和解码、图像缩放、立体视觉和模式识别等,可以将图像块和像素映射到并行处理线程。实际上,许多图像渲染和处理领域之外的算法都通过数据并行处理进行加速,从一般的信号处理或物理模拟到计算金融或计算生物学。
来源
高级阅读
一些有趣的事实:
引用:
this answer">这个答案中提到:“我写了一个 C++ 矩阵乘法,速度和 Matlab 一样快,但需要一些小心。(在 Matlab 开始使用 GPU 之前)。”