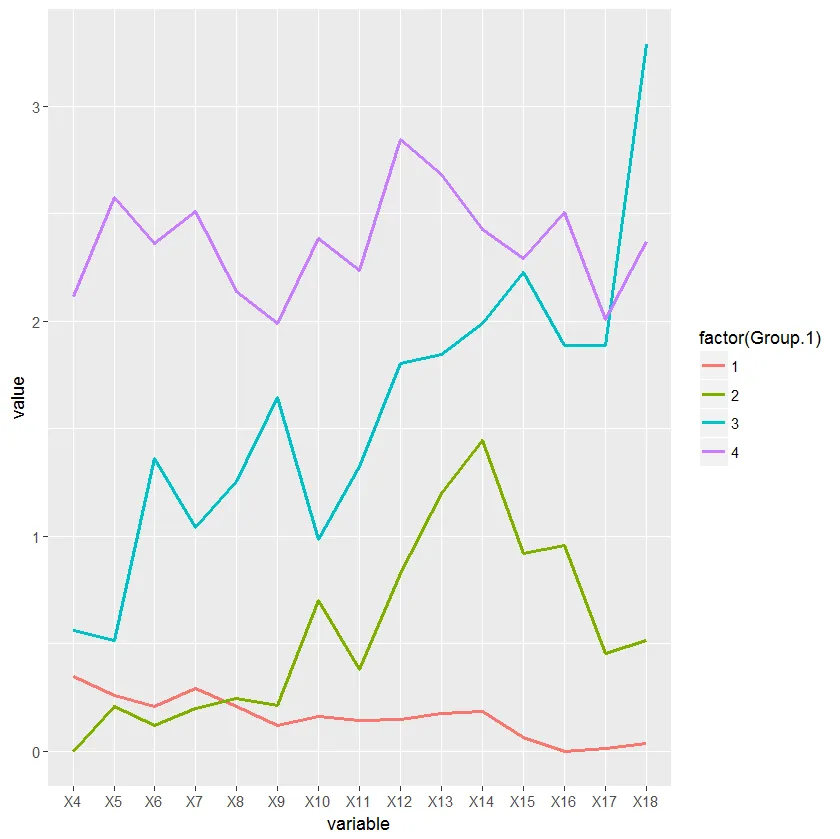
我有一个数据集,包括4种不同基因型小鼠的每日饮水量。我正在尝试编写一个脚本,根据它们的饮水模式将这些动物分类,并使用分层聚类分析创建一个纵向图表,绘制每个簇的平均饮水量在几天内的变化情况。
为此,我首先按以下方式创建了分层聚类簇:
问题是我从分层聚类中得到的数字与cutree函数分配的数字不一致。虽然聚类将分支从1到4自下而上排序,但cutree函数使用了其他我不熟悉的排序参数。因此,聚类图和进食图中的标签不匹配。
我是编程新手,所以我肯定使用了太多冗余行和循环,因此我的代码可以缩短,但如果你们能帮我解决这个特定的问题,我会非常高兴。 数据集 聚类: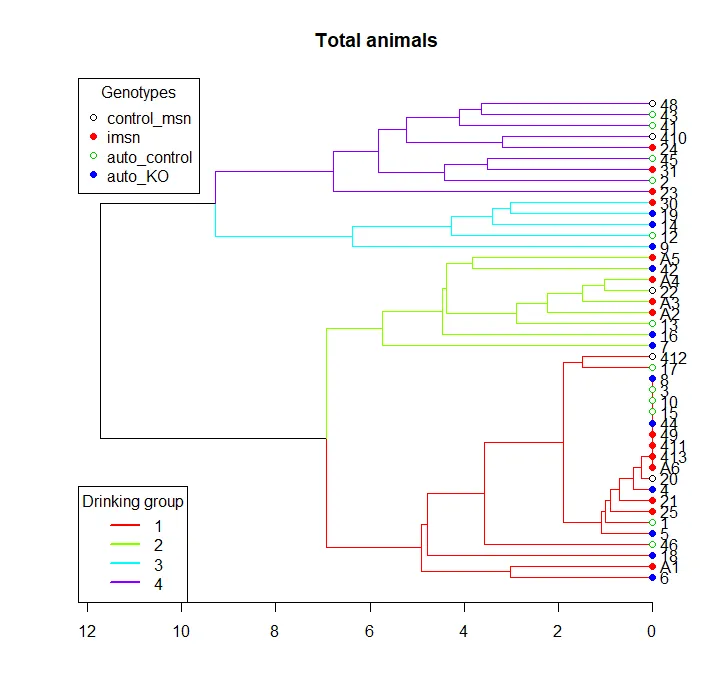 进食图:
进食图: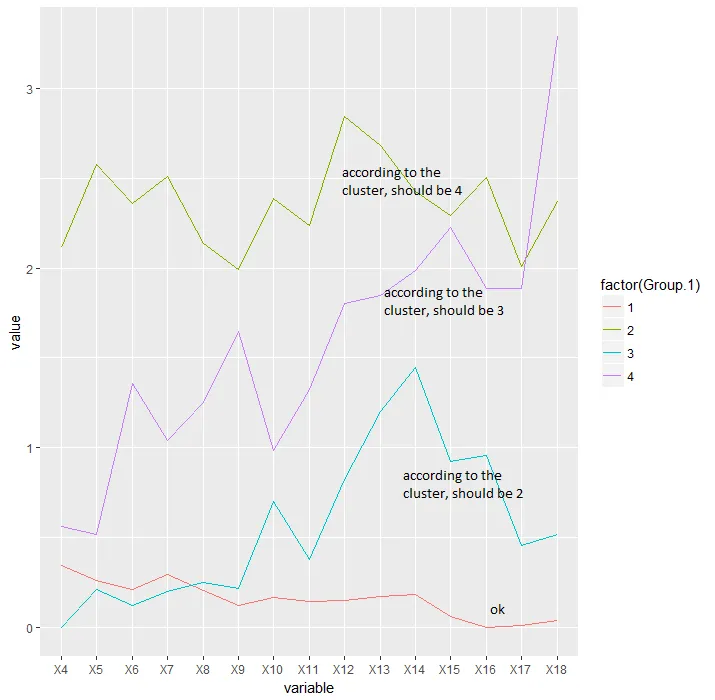
为此,我首先按以下方式创建了分层聚类簇:
library("dendextend")
library("ggplot2")
library("reshape2")
data=read.csv("data.csv", header=T, row.names=1)
trimmed=data[, -ncol(data)]
hc <- as.dendrogram(hclust(dist(trimmed)))
labels.drk=data[,ncol(data)]
groups.drk=labels.drk[order.dendrogram(hc)]
genotypes=as.character(unique(data[,ncol(data)]))
k=4
cluster_cols=rainbow(k)
hc <- hc %>%
color_branches(k = k, col=cluster_cols) %>%
set("branches_lwd", 1) %>%
set("leaves_pch", rep(c(21, 19), length(genotypes))[groups.drk]) %>%
set("leaves_col", palette()[groups.drk])
plot(hc, main="Total animals" ,horiz=T)
legend("topleft", legend=genotypes,
col=palette(), pch = rep(c(21,19), length(genotypes)),
title="Genotypes")
legend("bottomleft", legend=1:k,
col=cluster_cols, lty = 1, lwd = 2,
title="Drinking group")
然后我使用cutree函数来评估哪些动物属于哪个组,以便绘制每个组的平均饮水量。
groups<-cutree(hc, k=k, order_clusters_as_data = FALSE))
x<-cbind(data,groups)
intake_avg=aggregate(data[, -ncol(data)], list(x$groups), mean, header=T)
df <- melt(intake_avg, id.vars = "Group.1")
ggplot(df, aes(variable, value, group=factor(Group.1))) + geom_line(aes(color=factor(Group.1)))
问题是我从分层聚类中得到的数字与cutree函数分配的数字不一致。虽然聚类将分支从1到4自下而上排序,但cutree函数使用了其他我不熟悉的排序参数。因此,聚类图和进食图中的标签不匹配。
我是编程新手,所以我肯定使用了太多冗余行和循环,因此我的代码可以缩短,但如果你们能帮我解决这个特定的问题,我会非常高兴。 数据集 聚类:
进食图: