我有一个相当大的数据集,约75,000个观测值和7列,包含警报数据细节,这些细节
样例数据集如下:
使用stats:hclust可以得到一个簇,它能很好地代表数据,并且能够区分出这个样本中所有观测值中的两个主要警报事件簇(即树状图中的观测编号是应该被分组在一起的警报事件)。
stats:hclust无法支持(会崩溃RStudio)。通过一些搜索,我发现 Rclusterpp.hclust 可以降低层次聚类的复杂性和资源分配,于是尝试了一下。它大约需要5分钟左右并提供一个树状图,但是如果我尝试使用cutree,并指定高度或聚类数,就会得到奇怪的结果。当我使用38个观测值的小样本时,我看到了同样的问题,如下所示。是我的操作有误还是Rclusterpp.hclust包存在问题?(在R 3.4.1中运行包3.4.1)。样例数据集如下:
dataset
# DAY COUNT LOCATION M1 M2 HOURS SOURCE
#1 238 2 222307 1 1 5437 1008
#2 238 1 222307 2 1 5437 1008
#3 238 5 222307 3 2 5437 1008
#4 238 2 222307 4 3 5437 1008
#5 238 14 222307 5 1 5437 1008
#6 238 4 222307 5 1 5437 1008
#7 238 14 222307 6 2 5437 1008
#8 238 3 222307 1 1 5437 1008
#9 238 1 222307 2 1 5437 1008
#10 238 1 222307 4 3 5437 1008
#11 238 2 222307 4 3 5437 1008
#12 238 2 222307 4 3 5437 1008
#13 238 5 222307 5 1 5437 1008
#14 238 11 222307 5 1 5437 1008
#15 238 1 222307 5 1 5437 1008
#16 238 3 222307 5 1 5437 1008
#17 238 18 222307 6 2 5437 1008
#18 238 2 222307 7 4 5437 9
#19 238 2 222307 8 4 5437 10
#20 238 3 222307 9 5 5437 1008
#21 238 2 222307 10 6 5437 865
#22 238 9 222307 11 7 5437 10
#23 238 2 222307 12 7 5437 10
#24 238 1 222307 12 7 5437 10
#25 238 5 222307 11 7 5437 10
#26 238 2 222307 8 4 5437 10
#27 238 3 222307 13 8 5437 864
#28 238 3 222307 14 8 5437 864
#29 238 1 222307 11 7 5437 10
#30 238 3 222307 11 7 5437 10
#31 238 2 222307 15 7 5437 10
#32 238 5 222307 11 7 5437 10
#33 238 2 222307 16 7 5437 10
#34 238 2 222307 17 7 5437 10
#35 238 3 222307 18 7 5437 10
#36 238 2 222307 15 7 5437 10
#37 238 6 222307 11 7 5437 10
#38 238 3 222307 19 7 5437 10
DAY、HOURS和COUNT是实数,而LOCATION、M1、M2和SOURCE是数字编码的类别值。使用stats:hclust可以得到一个簇,它能很好地代表数据,并且能够区分出这个样本中所有观测值中的两个主要警报事件簇(即树状图中的观测编号是应该被分组在一起的警报事件)。
d1 <- dist((as.matrix(scale(dataset))))
hc1 <- hclust(d1, method = "single")
cutree(hc1,2)
# 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 #27 28 29 30 31 32 33 34 35 36 37 38
# 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 2 2 1 1 2 2 2 2 2 #1 1 2 2 2 2 2 2 2 2 2 2
plot(hc1)
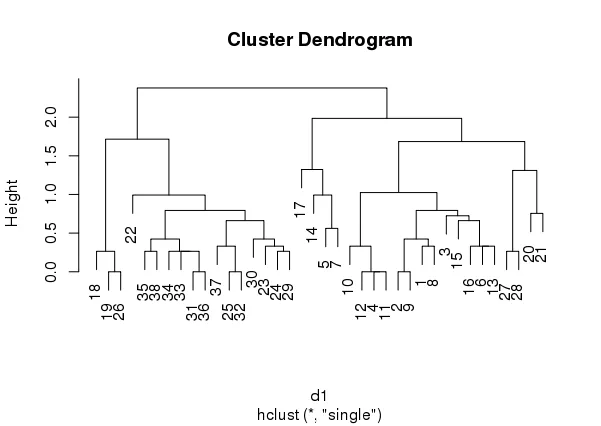
然而,如果我在Rclusterpp:hclust中进行相同操作,我得到的聚类比我指定的要多(在这个例子中,我要求2个聚类,但是实际上得到了3个)。当我在我的大型数据集上运行此操作时,我只要求几个聚类,就会得到近20,000个聚类。
d2 <- dist((as.matrix(scale(dataset))))
hc2 <- Rclusterpp.hclust(d2, method = "single")
cutree(hc2,2)
# 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 #27 28 29 30 31 32 33 34 35 36 37 38
# 1 1 1 1 1 1 1 1 1 1 2 2 1 1 1 1 1 3 3 1 1 3 3 3 3 3 #1 1 3 3 3 3 3 3 3 3 3 3
plot(hc2)
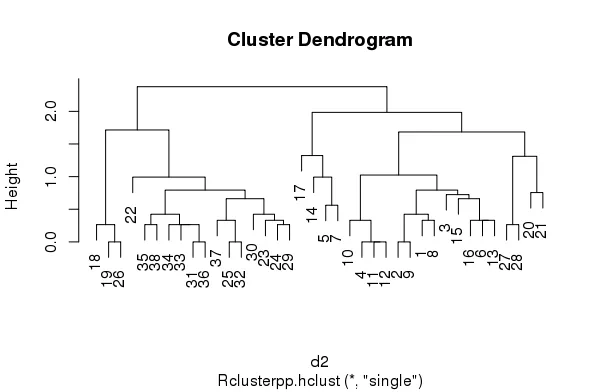
不知道为什么会发生这种情况呢?谢谢。