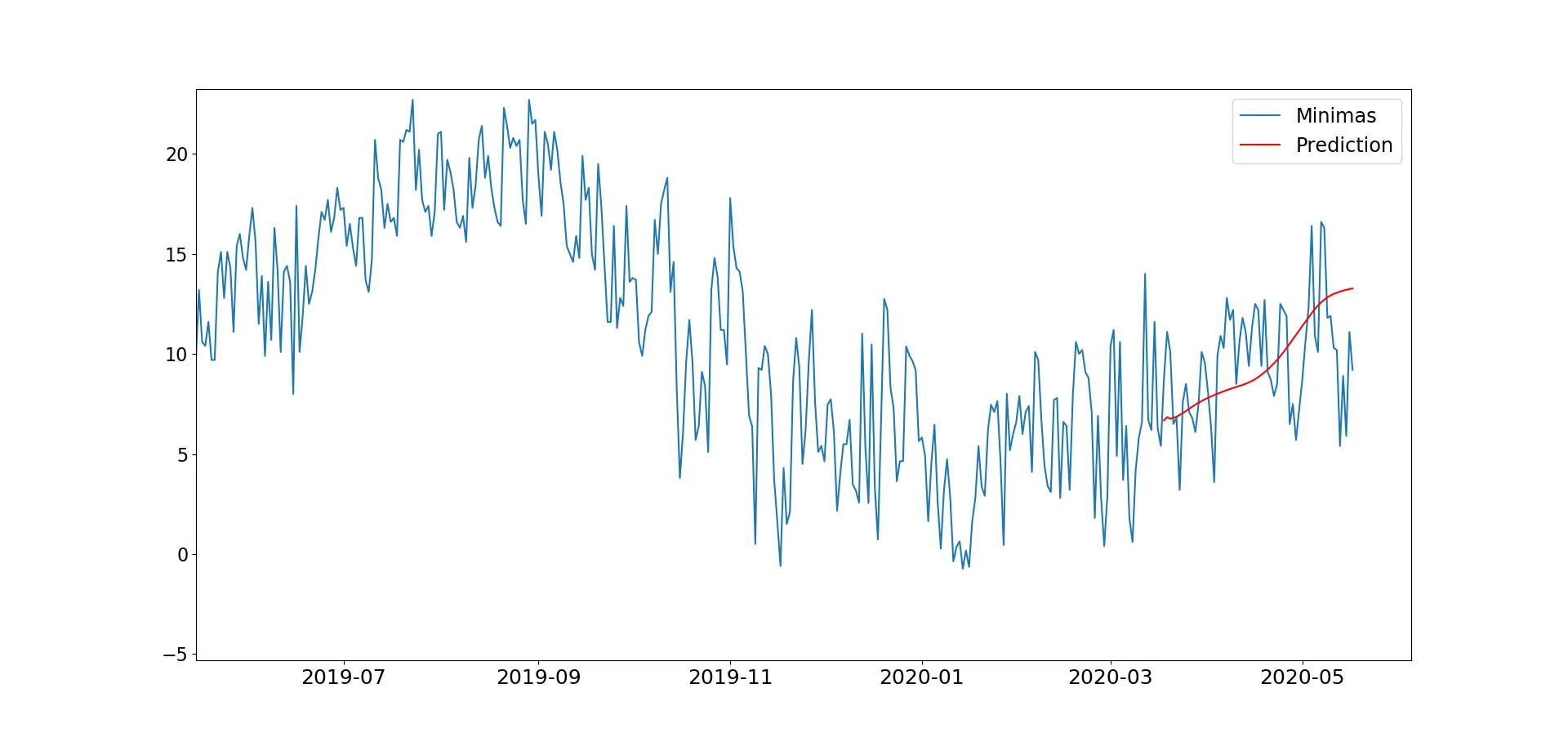
我正在学习如何将神经网络应用于时间序列,因此我调整了一个LSTM示例,以预测每日温度数据。然而,我发现结果非常糟糕,如图所示。(目前为了节省时间,我只预测最后92天的数据)。
这是我实现的代码。数据是一个三列的数据框(最低温度、最高温度和平均日温度),但我每次只使用其中一列。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from statsmodels.tools.eval_measures import rmse
from sklearn.preprocessing import MinMaxScaler
from keras.preprocessing.sequence import TimeseriesGenerator
from keras.models import Sequential
from keras.layers import Dense
from keras.layers import LSTM
from keras.layers import Dropout
import warnings
warnings.filterwarnings("ignore")
input_file2 = "TemperaturasCampillos.txt"
seriesT = pd.read_csv(input_file2,sep = "\t", decimal = ".", names = ["Minimas","Maximas","Medias"])
seriesT[seriesT==-999]=np.nan
date1 = '2010-01-01'
date2 = '2010-09-01'
date3 = '2020-05-17'
date4 = '2020-12-31'
mydates = pd.date_range(date2, date3).tolist()
seriesT['Fecha'] = mydates
seriesT.set_index('Fecha',inplace=True) # Para que los índices sean fechas y así se ponen en el eje x de forma predeterminada
seriesT.index = seriesT.index.to_pydatetime()
df = seriesT.drop(seriesT.columns[[1, 2]], axis=1) # df.columns is zero-based pd.Index
n_input = 92
train, test = df[:-n_input], df[-n_input:]
scaler = MinMaxScaler()
scaler.fit(train)
train = scaler.transform(train)
test = scaler.transform(test)
#n_input = 365
n_features = 1
generator = TimeseriesGenerator(train, train, length=n_input, batch_size=1)
model = Sequential()
model.add(LSTM(200, activation='relu', input_shape=(n_input, n_features)))
model.add(Dropout(0.15))
model.add(Dense(1))
model.compile(optimizer='adam', loss='mse')
model.fit_generator(generator,epochs=150)
#create an empty list for each of our 12 predictions
#create the batch that our model will predict off of
#save the prediction to our list
#add the prediction to the end of the batch to be used in the next prediction
pred_list = []
batch = train[-n_input:].reshape((1, n_input, n_features))
for i in range(n_input):
pred_list.append(model.predict(batch)[0])
batch = np.append(batch[:,1:,:],[[pred_list[i]]],axis=1)
df_predict = pd.DataFrame(scaler.inverse_transform(pred_list),
index=df[-n_input:].index, columns=['Prediction'])
df_test = pd.concat([df,df_predict], axis=1)
plt.figure(figsize=(20, 5))
plt.plot(df_test.index, df_test['Minimas'])
plt.plot(df_test.index, df_test['Prediction'], color='r')
plt.legend(loc='best', fontsize='xx-large')
plt.xticks(fontsize=18)
plt.yticks(fontsize=16)
plt.show()
如果您点击图像链接,可以看到我得到了一个过于平滑的预测结果,可以看到季节性,但这不是我期望的。此外,我尝试向所示的神经网络添加更多层,因此该网络看起来类似于:
#n_input = 365
n_features = 1
generator = TimeseriesGenerator(train, train, length=n_input, batch_size=1)
model = Sequential()
model.add(LSTM(200, activation='relu', input_shape=(n_input, n_features)))
model.add(LSTM(128, activation='relu'))
model.add(LSTM(256, activation='relu'))
model.add(LSTM(128, activation='relu'))
model.add(LSTM(64, activation='relu'))
model.add(LSTM(n_features, activation='relu'))
model.add(Dropout(0.15))
model.add(Dense(1))
model.compile(optimizer='adam', loss='mse')
model.fit_generator(generator,epochs=100)
但是我遇到了这个错误:
ValueError: 输入0与lstm_86层不兼容:期望ndim=3,发现ndim=2
当然,由于模型表现不佳,我不能保证外部样本的预测准确性。 为什么我不能在网络中添加更多层?如何提高性能?