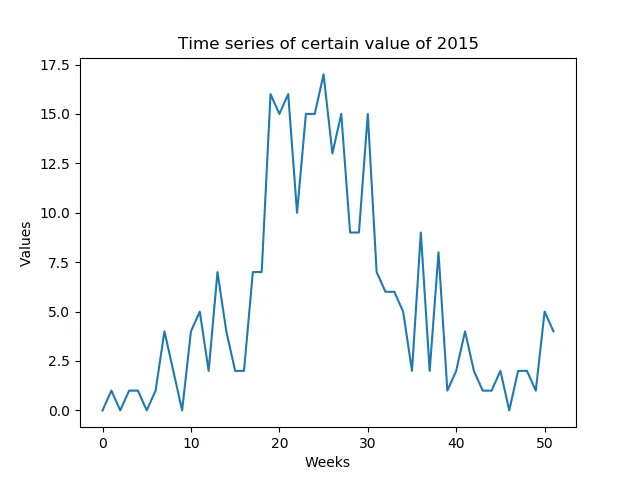
我希望能够预测那些每周可预测的值(低信噪比)。我需要预测一整个年度形成的时间序列,该年度由一年中的每周组成(52个数值-图1)。
在Keras中,该模型的代码如下:
y = y.reshape(y.shape[0], 52, 1)
X = X.reshape(X.shape[0], 52, 1)
# design network
model = Sequential()
model.add(LSTM(n_neurons, input_shape=(X.shape[1], X.shape[2]), return_sequences=True))
model.add(TimeDistributed(Dense(1)))
model.compile(loss='mean_squared_error', optimizer='adam')
# fit network
model.fit(X, y, epochs=n_epochs, batch_size=n_batch, verbose=2)
第二个问题: 另一个想法是用1个输入和1个输出来训练算法,但是在测试期间,我如何预测整个2015年的时间序列而不查看“1个输入”?测试数据将具有不同的形状比训练数据。