我一直在玩具数据集上尝试理解shap库和使用方法。我发现一个问题,即catboost回归模型的特征重要性与shap库中的summary_plot的特征重要性不同。
我正在分析X_train集上的model.feature_importances_的特征重要性以及X_test集上的shap explainer的summary plot。
以下是我的源代码 -
我正在分析X_train集上的model.feature_importances_的特征重要性以及X_test集上的shap explainer的summary plot。
以下是我的源代码 -
import catboost
from catboost import *
import shap
shap.initjs()
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
X,y = shap.datasets.boston()
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.25, random_state=42)
# Train Model
model = CatBoostRegressor(iterations=300, learning_rate=0.1, random_seed=123)
model.fit(X_train, y_train, verbose=False, plot=False)
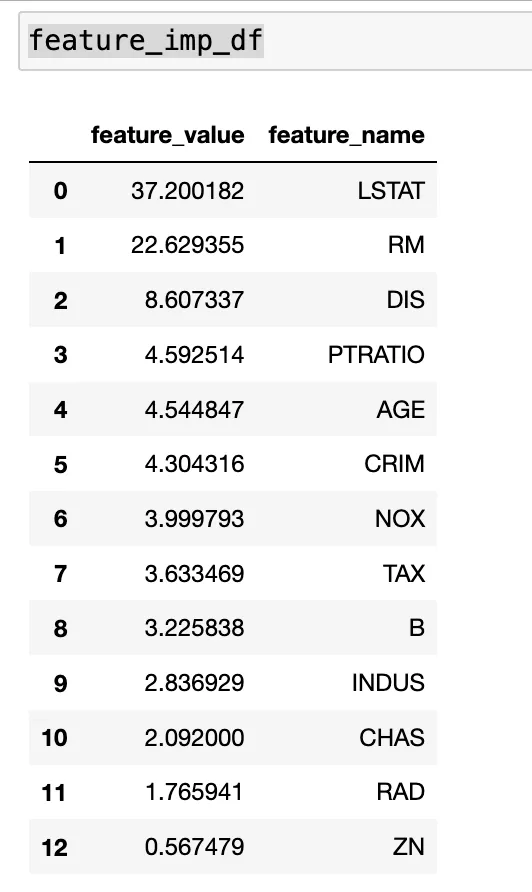
# Compute feature importance dataframe
feat_imp_list = list(zip ( list(model.feature_importances_) , model.feature_names_) )
feature_imp_df = pd.DataFrame(sorted(feat_imp_list, key=lambda x: x[0], reverse=True) , columns = ['feature_value','feature_name'])
feature_imp_df
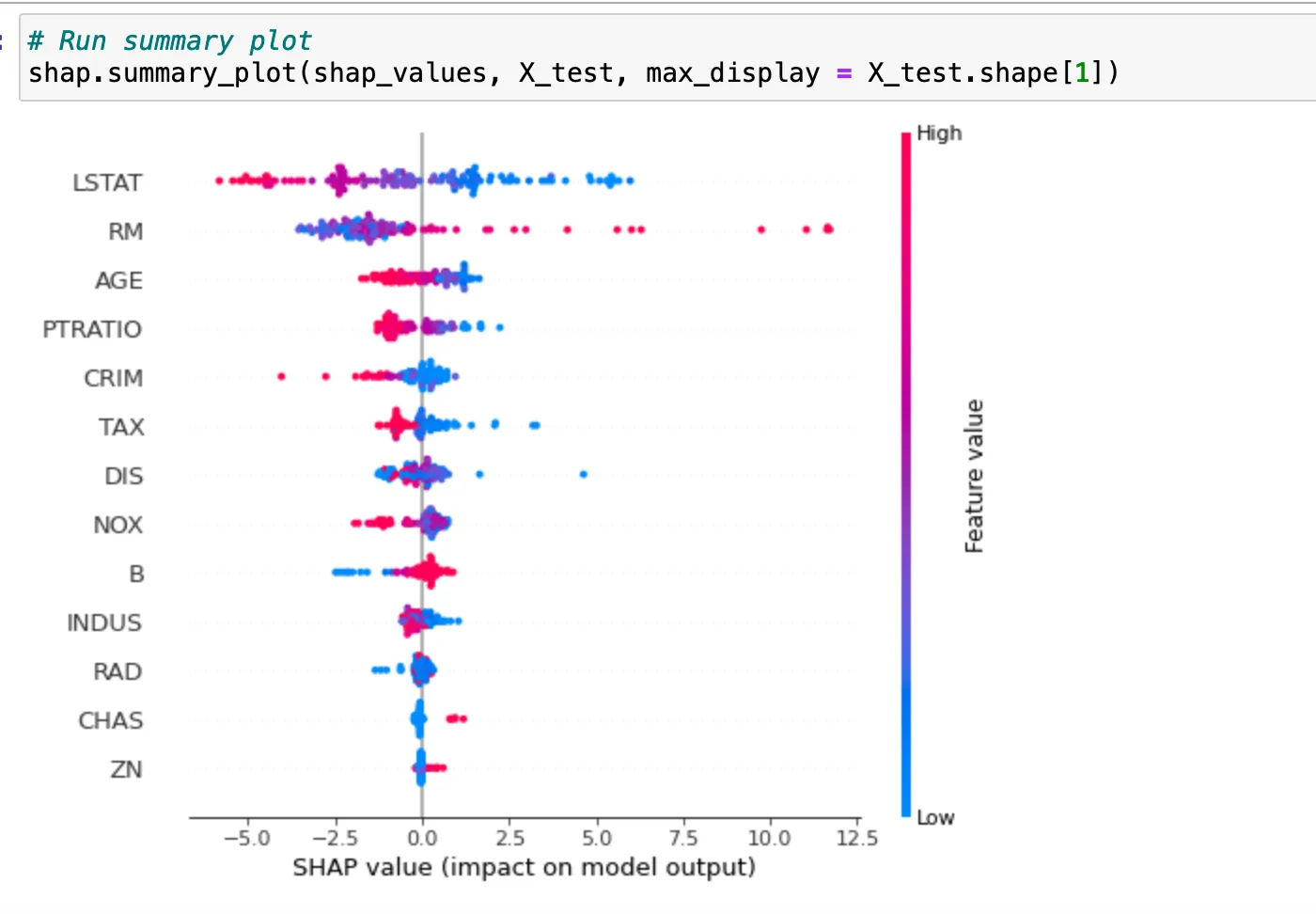
# Run shap explainer on X_test set
explainer = shap.TreeExplainer(model)
shap_values = explainer.shap_values(X_test)
- 链接
- 链接
- Amit Kumar