我想知道如何使用
我在这里看到,对于二元分类问题,您可以通过以下方式提取每个类别的
如何修改这段代码使其适用于多类问题?
我需要提取与第6类特征重要性相关的shap值。
以下是我的代码开头:
shap算法生成特定类别的特征重要性表?
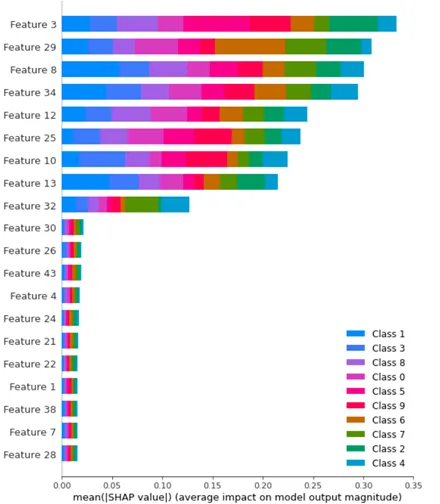
我在这里看到,对于二元分类问题,您可以通过以下方式提取每个类别的
shap:# shap values for survival
sv_survive = sv[:,y,:]
# shap values for dying
sv_die = sv[:,~y,:]
如何修改这段代码使其适用于多类问题?
我需要提取与第6类特征重要性相关的shap值。
以下是我的代码开头:
from sklearn.datasets import make_classification
import seaborn as sns
import numpy as np
import pandas as pd
from matplotlib import pyplot as plt
import pickle
import joblib
import warnings
import shap
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import RandomizedSearchCV, GridSearchCV
f, (ax1,ax2) = plt.subplots(nrows=1, ncols=2,figsize=(20,8))
# Generate noisy Data
X_train,y_train = make_classification(n_samples=1000,
n_features=50,
n_informative=9,
n_redundant=0,
n_repeated=0,
n_classes=10,
n_clusters_per_class=1,
class_sep=9,
flip_y=0.2,
#weights=[0.5,0.5],
random_state=17)
X_test,y_test = make_classification(n_samples=500,
n_features=50,
n_informative=9,
n_redundant=0,
n_repeated=0,
n_classes=10,
n_clusters_per_class=1,
class_sep=9,
flip_y=0.2,
#weights=[0.5,0.5],
random_state=17)
model = RandomForestClassifier()
parameter_space = {
'n_estimators': [10,50,100],
'criterion': ['gini', 'entropy'],
'max_depth': np.linspace(10,50,11),
}
clf = GridSearchCV(model, parameter_space, cv = 5, scoring = "accuracy", verbose = True) # model
my_model = clf.fit(X_train,y_train)
print(f'Best Parameters: {clf.best_params_}')
# save the model to disk
filename = f'Testt-RF.sav'
pickle.dump(clf, open(filename, 'wb'))
explainer = Explainer(clf.best_estimator_)
shap_values_tr1 = explainer.shap_values(X_train)
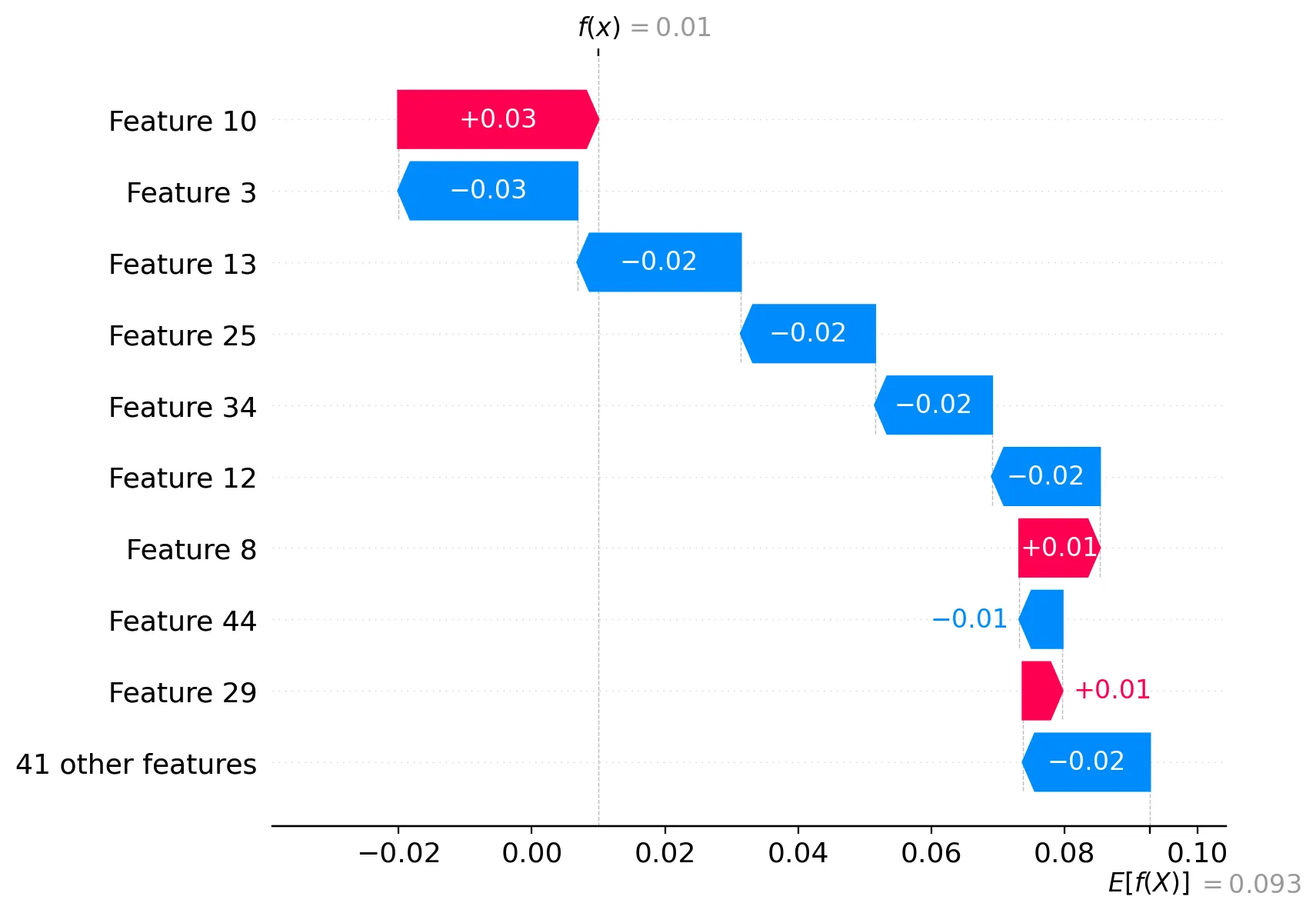
idx数据点上进行确认。要查看平均情况下的情况(您的摘要情节),我们需要聚合sv_cls(或多或少为np.abs(sv_cls). mean(0),但您需要检查形状。 - Sergey Bushmanovsv_cls并对聚合后的shap值进行排序,那么我们可以推断出我们现在拥有了该特定类别的特征重要性集合,这种说法正确吗? - Joe