让我们准备一些二元分类数据:
from seaborn import load_dataset
from sklearn.model_selection import train_test_split
from lightgbm import LGBMClassifier
import shap
titanic = load_dataset("titanic")
X = titanic.drop(["survived","alive","adult_male","who",'deck'],1)
y = titanic["survived"]
features = X.columns
cat_features = []
for cat in X.select_dtypes(exclude="number"):
cat_features.append(cat)
X[cat] = X[cat].astype("category").cat.codes.astype("category")
X_train, X_val, y_train, y_val = train_test_split(X,y,train_size=.8, random_state=42)
clf = LGBMClassifier(max_depth=3, n_estimators=1000, objective="binary")
clf.fit(X_train,y_train, eval_set=(X_val,y_val), early_stopping_rounds=100, verbose=100)
回答您的问题,要按每个类别提取shap值,则可以通过类别标签对它们进行子集划分。
explainer = shap.TreeExplainer(clf)
shap_values = explainer.shap_values(X_train)
sv = np.array(shap_values)
y = clf.predict(X_train).astype("bool")
sv_survive = sv[:,y,:]
sv_die = sv[:,~y,:]
然而,更有趣的问题是您可以用这些值做什么。
一般来说,通过查看summary_plot(针对整个数据集),可以获得有价值的见解:
shap.summary_plot(shap_values[1], X_train.astype("float"))
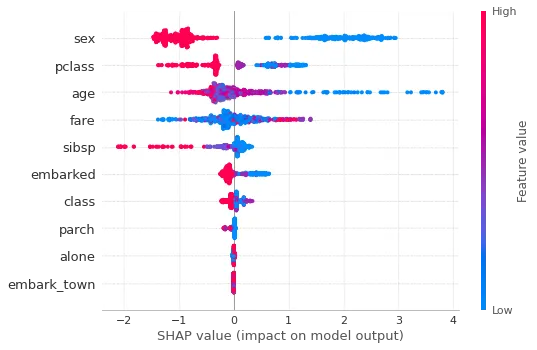
整体解读:
- 性别(sex)、船舱等级(pclass)和年龄是决定结果最具影响力的特征。
- 男性、较不富裕、年龄较大将降低生存几率。
以下为全球前3个最具影响力的特征:
idx = np.abs(sv[1,:,:]).mean(0).argsort()
features[idx[:-4:-1]]
如果你想按班级进行分析,你可以单独为幸存者(
sv[1,y,:])进行操作:
idx = sv[1,y,:].mean(0).argsort()
features[idx[:-4:-1]]
对于那些没有存活下来的人(
sv[0,~y,:] ),情况相同:
idx = sv[0,~y,:].mean(0).argsort()
features[idx[:3]]
注意,这里使用的是平均shap值,并且我们对幸存者最大值感兴趣,对那些非幸存者的最低值(接近0的最低值可能意味着根本没有恒定的单向影响)。使用绝对值均值也许有意义,但解释将是最具影响力的,不论方向如何。
为了做出明智的选择,无论是喜欢均值还是绝对值的均值,都必须了解以下事实:
- shap值可以是正数也可以是负数
- shap值是对称的,并且增加/减少一个类别的概率会通过相同的量减少/增加另一个类别的概率(因为p₁ = 1-p₀)
证明:
sv = np.array(shap_values)
ev = np.array(explainer.expected_value)
sv_died, sv_survived = sv[:,0,:]
print(sv_died, sv_survived, sep="\n")
很可能你会发现性别和年龄对幸存者和非幸存者的影响最大;因此,与其分析每个类别中最具影响力的特征,不如看看是什么使得两名相同性别和年龄的乘客中的一个幸存,另一个未能幸存(提示:在数据集中找到这样的情况,将一个作为背景输入,然后分析另一个的 shap 值,或者尝试将一个类与另一个类作为背景进行分析)。
您可以使用 dependence_plot 进行进一步分析(全局或按类别基础上)。
shap.dependence_plot("sex", shap_values[1], X_train)
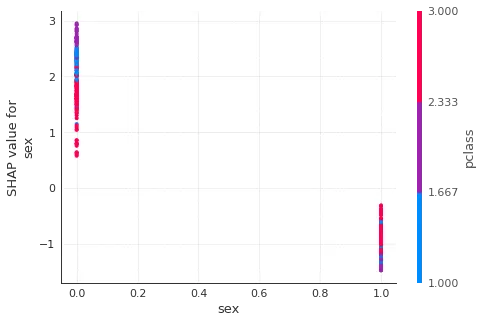
总体解释:
- 男性存活率较低(shap值较低)
- 票价等级(富裕程度)是影响因素的次要因素:对于女性来说,票价等级越高(贫困程度越低),生还几率降低,而对于男性来说则相反。