我有一个移植实验,涉及四个地点和四种基质(每个地点取自不同基质)。我已经确定了每个种群在每个地点和基质组合中的存活情况。该实验已被复制三次。
我创建了一个lmm,如下所示:
我想使用predict命令提取预测结果,例如:
然后提取标准误差,以便我可以将它们与预测一起绘制,生成类似以下图表的内容:
我创建了一个lmm,如下所示:
Survival.model <- lmer(Survival ~ Location + Substrate + Location:Substrate + (1|Replicate), data=Transplant.Survival,, REML = TRUE)
我想使用predict命令提取预测结果,例如:
Survival.pred <- predict(Survival.model)
然后提取标准误差,以便我可以将它们与预测一起绘制,生成类似以下图表的内容:
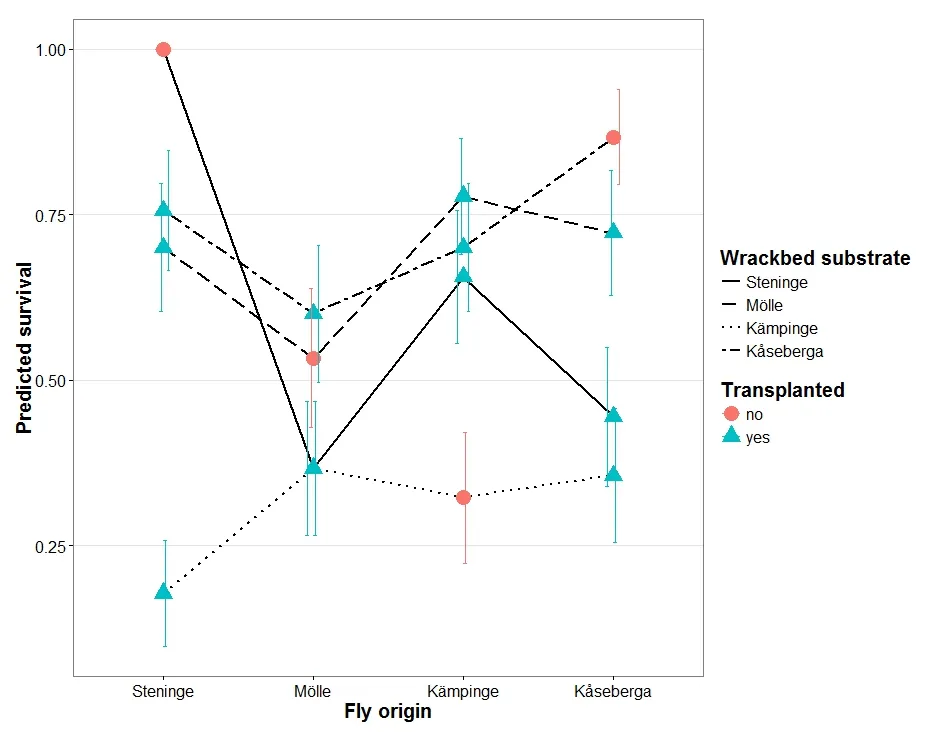
我知道如何使用标准glm来完成这个任务(这也是我创建示例图的方式),但我不确定是否可以或应该使用lmm。
作为线性混合模型的新用户,我是否缺少了一些基础知识?
我在Stack Overflow上找到了post,但并没有得到帮助。
根据RHertel的评论,也许我应该这样表达问题:如何绘制我的lmer模型结果的模型估计值和置信区间,以便我可以获得与上面创建的类似的图形?
示例数据:
Transplant.Survival <- structure(list(Location = structure(c(1L, 1L, 1L, 1L, 1L, 1L,
1L, 1L, 1L, 1L, 1L, 2L, 2L, 2L, 2L, 2L, 2L, 2L, 2L, 2L, 2L, 2L,
3L, 3L, 3L, 3L, 3L, 3L, 3L, 3L, 3L, 3L, 3L, 3L, 4L, 4L, 4L, 4L,
4L, 4L, 4L, 4L, 4L, 4L, 4L, 4L), .Label = c("Steninge", "Molle",
"Kampinge", "Kaseberga"), class = "factor"), Substrate = structure(c(1L,
1L, 1L, 2L, 2L, 2L, 3L, 3L, 4L, 4L, 4L, 1L, 1L, 2L, 2L, 2L, 3L,
3L, 3L, 4L, 4L, 4L, 1L, 1L, 1L, 2L, 2L, 2L, 3L, 3L, 3L, 4L, 4L,
4L, 1L, 1L, 1L, 2L, 2L, 2L, 3L, 3L, 3L, 4L, 4L, 4L), .Label = c("Steninge",
"Molle", "Kampinge", "Kaseberga"), class = "factor"), Replicate = structure(c(1L,
2L, 3L, 1L, 2L, 3L, 1L, 2L, 1L, 2L, 3L, 2L, 3L, 1L, 2L, 3L, 1L,
2L, 3L, 1L, 2L, 3L, 1L, 2L, 3L, 1L, 2L, 3L, 1L, 2L, 3L, 1L, 2L,
3L, 1L, 2L, 3L, 1L, 2L, 3L, 1L, 2L, 3L, 1L, 2L, 3L), .Label = c("1",
"2", "3"), class = "factor"), Survival = c(1, 1, 1, 0.633333333333333,
0.966666666666667, 0.5, 0.3, 0.233333333333333, 0.433333333333333,
0.966666666666667, 0.866666666666667, 0.5, 0.6, 0.266666666666667,
0.733333333333333, 0.6, 0.3, 0.5, 0.3, 0.633333333333333, 0.9,
0.266666666666667, 0.633333333333333, 0.7, 0.633333333333333,
0.833333333333333, 0.9, 0.6, 0.166666666666667, 0.333333333333333,
0.433333333333333, 0.6, 0.9, 0.6, 0.133333333333333, 0.566666666666667,
0.633333333333333, 0.633333333333333, 0.766666666666667, 0.766666666666667,
0.0333333333333333, 0.733333333333333, 0.3, 1.03333333333333,
0.6, 1)), .Names = c("Location", "Substrate", "Replicate", "Survival"
), class = "data.frame", row.names = c(NA, -46L))
lme4没有为它们实现函数的原因。您只需要前端标准误差吗?后端标准误差?还是组合标准误差?此外,您的方差矩阵结构也很重要。 - alexwhitworth