与 @mtoto 类似,我也不熟悉
library(plm) 或
library(pglm)。但是,
plm 的预测方法可用,只是没有被导出。
编辑:对于由 plm::plm() 生成的模型,自从 plm CRAN 版本 2.6-2 发布以来,有一个可用的 predict 方法。pglm 没有预测方法。
R> methods(class= "plm")
[1] ercomp fixef has.intercept model.matrix pFtest plmtest plot pmodel.response
[9] pooltest predict residuals summary vcovBK vcovHC vcovSCC
R> methods(class= "pglm")
no methods found
值得注意的是,我不明白为什么你在工资数据中使用泊松模型。显然这不是一个泊松分布,因为它采用了非整数值(如下所示)。如果您愿意,可以尝试负二项式,但我不确定是否可以使用随机效应。但是您可以使用MASS::glm.nb。
> quantile(Unions$wage, seq(0,1,.1))
0
0.02790139 2.87570334 3.54965422 4.14864865 4.71605855 5.31824370 6.01422463 6.87414349 7.88514525 9.59904809 57.50431282
解决方案1:使用plm
punions$p <- predict(fit1, punions)
ggplot(punions, aes(x=exper, y=p)) +
geom_point() +
facet_wrap(rural ~ married)
方案2 - lme4
或者,您可以使用lme4软件包获取类似的拟合结果,该软件包已定义了预测方法:
library(lme4)
Unions$id <- factor(Unions$id)
fit3 <- lmer(wage ~ exper + rural + married + (1|id), data= Unions)
fit4 <- glmer(wage ~ exper + rural + married + (1|id), data= Unions, family= poisson(link= "log"))
R> fit1$coefficients
(Intercept) exper ruralyes marriedyes
3.7467469 0.3088949 -0.2442846 0.4781113
R> fixef(fit3)
(Intercept) exper ruralyes marriedyes
3.7150302 0.3134898 -0.1950361 0.4592975
我还没有运行泊松模型,因为它的规范明显是错误的。你可以进行某种变量转换来处理,或者使用负二项式。无论如何,让我们完成这个例子:
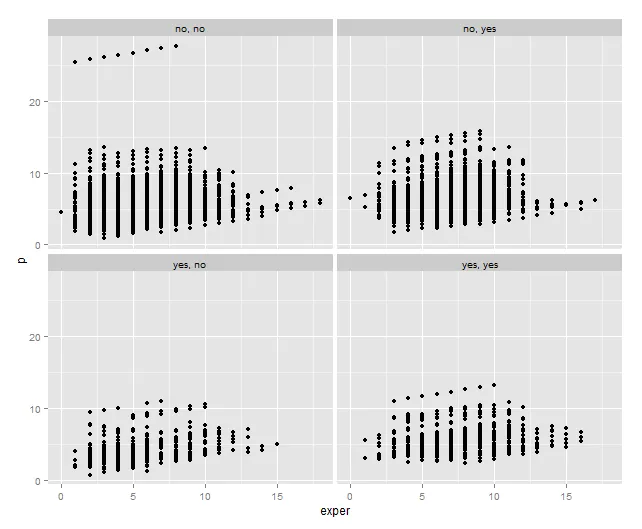
Unions$p <- predict(fit3, Unions)
ggplot(Unions, aes(x=exper, y=p)) +
geom_point() +
facet_wrap(rural ~ married)