我使用 MASS 的 polr 函数,对有序数据进行了比例几率累积logit模型拟合(例如,在描述不同种类奶酪喜好的数据上)。
data=read.csv("https://www.dropbox.com/s/psj74dx8ohnrdlp/cheese.csv?dl=1")
data$response=factor(data$response, ordered=T) # make response into ordered factor
head(data)
cheese response count
1 A 1 0
2 A 2 0
3 A 3 1
4 A 4 7
5 A 5 8
6 A 6 8
library(MASS)
fit=polr(response ~ cheese, weights=count, data=data, Hess=TRUE, method="logistic")
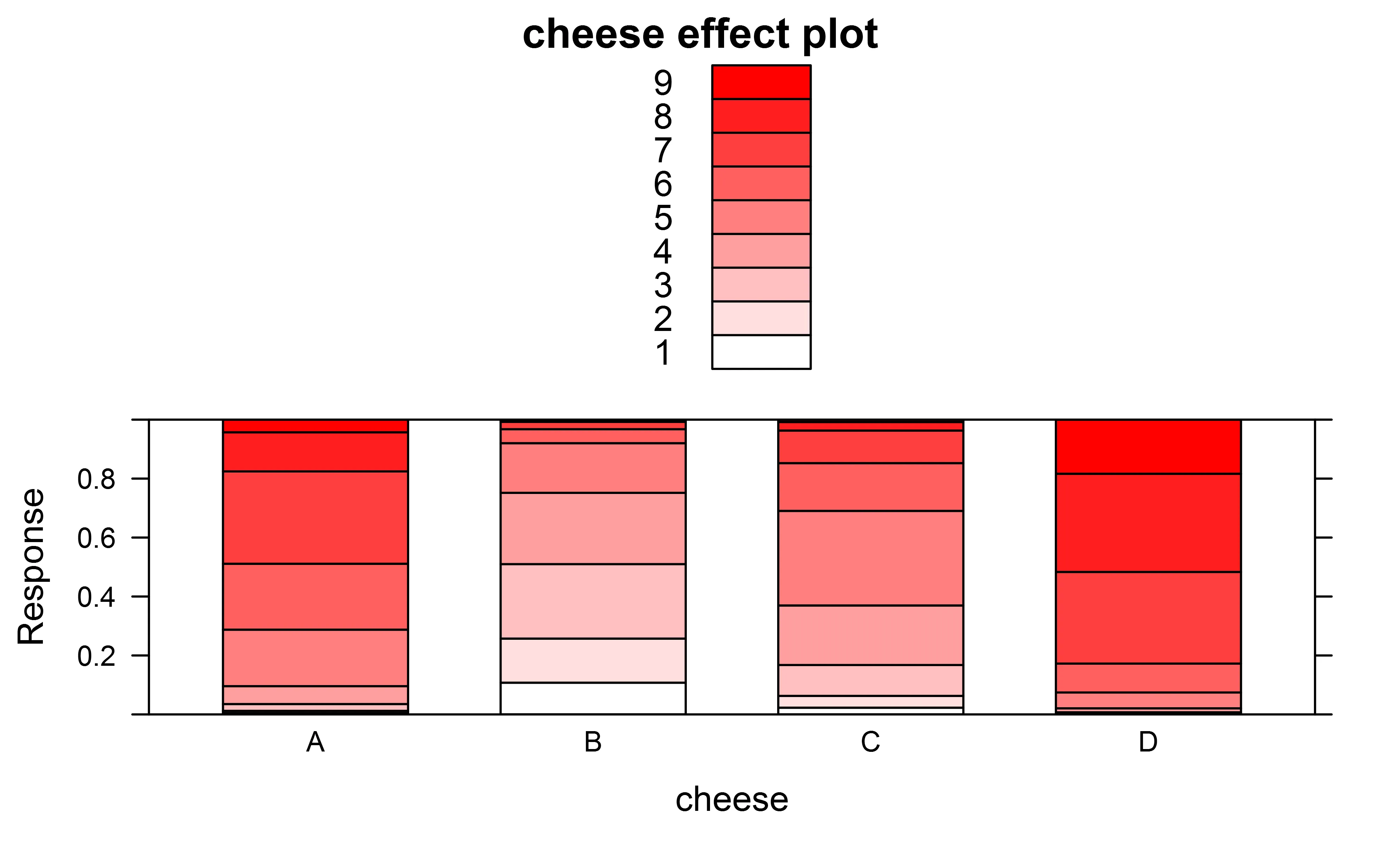
为了绘制模型预测结果,我使用了一个效果图来展示。
library(effects)
library(colorRamps)
plot(allEffects(fit),ylab="Response",type="probability",style="stacked",colors=colorRampPalette(c("white","red"))(9))
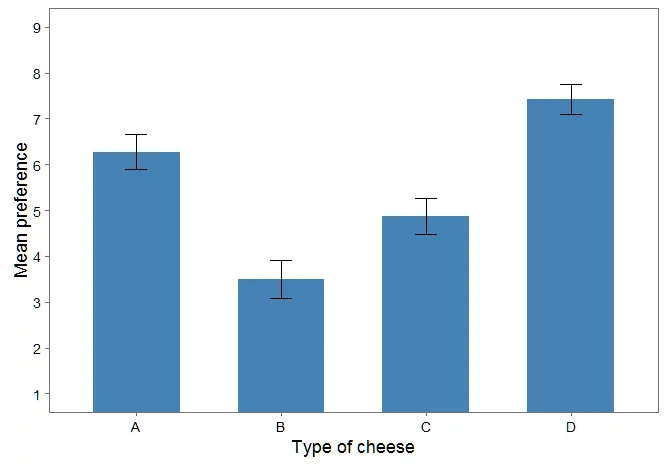
我想知道是否可以通过 effects 软件包报告的预测均值来绘制每种奶酪的平均喜好程度以及其中的95%置信区间。
编辑:最初我也询问了如何获得Tukey事后检验,但与此同时,我发现可以使用下列方法获取:
library(multcomp)
summary(glht(fit, mcp(cheese = "Tukey")))
或者使用包lsmeans:
summary(lsmeans(fit, pairwise ~ cheese, adjust="tukey", mode = "linear.predictor"),type="response")