我有一个长的pandas时间序列,如下:
2017-11-27 16:19:00 120.0
2017-11-30 02:40:35 373.4
2017-11-30 02:40:42 624.5
2017-12-01 14:15:31 871.8
2017-12-01 14:15:33 1120.0
2017-12-07 21:07:04 1372.2
2017-12-08 06:11:50 1660.0
2017-12-08 06:11:53 1946.7
2017-12-08 06:11:57 2235.3
2017-12-08 06:12:00 2521.3
....
dtype: float64
我希望将其及其导数一起绘制。根据定义,我用以下方式计算导数:
numer=myTimeSeries.diff()
denominat=myTimeSeries.index.to_series().diff().dt.total_seconds()/3600
derivative=numer/denominat
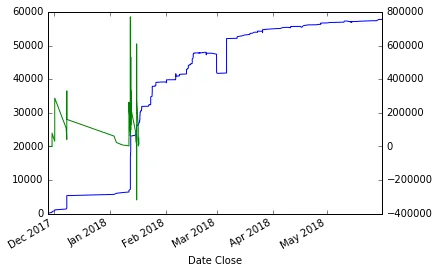
因为一些时间差(即分母)的值非常接近于零(有时甚至等于零),我在求导过程中得到了一些无穷大的值。实际上,我得到了这个:[
![]. [1]](https://istack.dev59.com/5zWbU.webp)
时间序列蓝色(左刻度),导数绿色(右刻度)
现在我想平滑导数以使其更易读。我尝试了不同的操作,例如:
- 在较高的周期上计算差异:
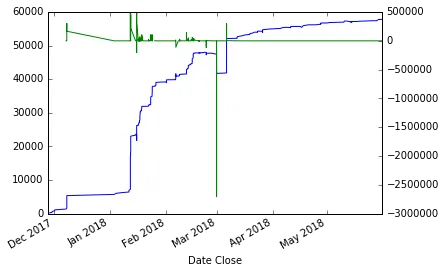
设置期数= 5,对于分子和分母
- 使用移动平均线:
smotDeriv=derivative.rolling(window=10,min_periods=3,center=True,win_type='boxcar').mean() 得到:
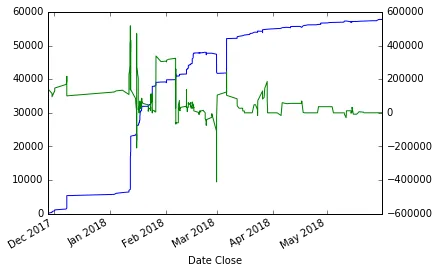
- 我也考虑过剪切值,但我不知道使用哪些有效值作为最小和最大值。我尝试了25%和75%的分位数,但没有什么优势。
我还尝试使用pykalman的卡尔曼滤波器:
derivative.fillna(0,inplace=True) kf = KalmanFilter(initial_state_mean=0) state_means,_ = kf.filter(derivative.values) state_means = state_means.flatten() indexDate=derivative.index derivativeKalman=pd.Series(state_means,index=indexDate)
以达到这个目的: