这个问题的各种版本之前已经被问过,我不确定是否应该在其中一个线程上提出我的问题或者开启一个新线程。以下是我的问题:
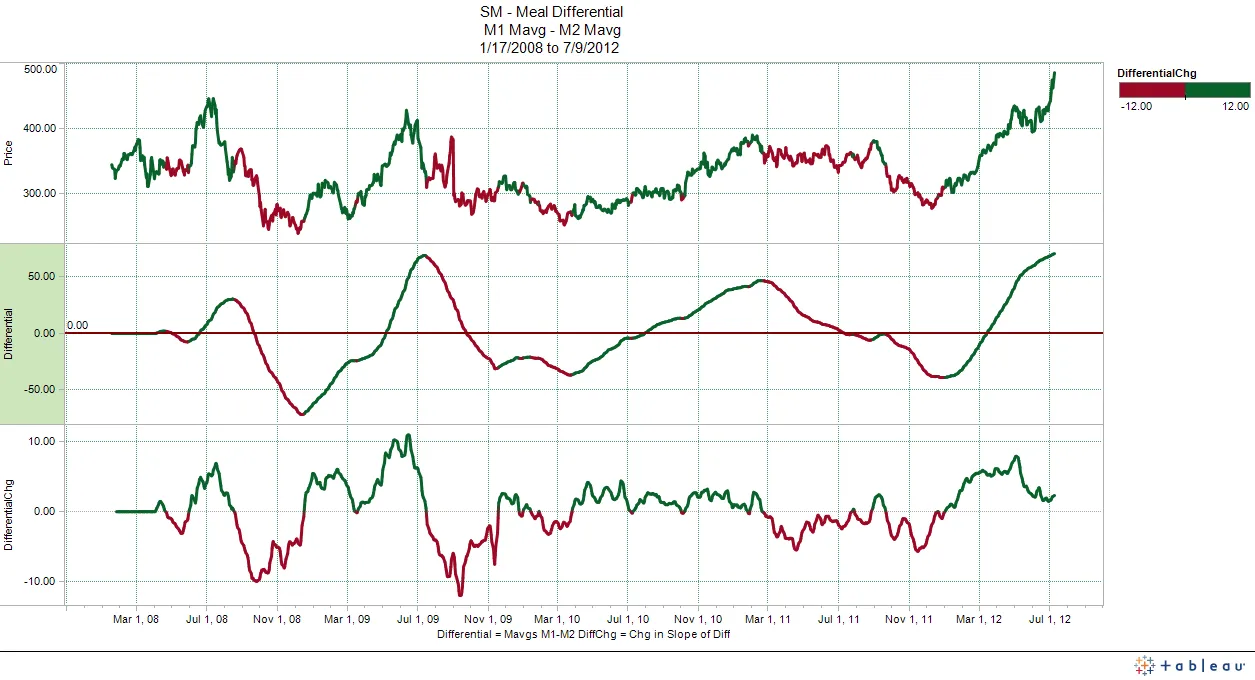
我有一个pandas数据帧,在其中有一列(例如:速度)我正在尝试绘制,并且还有另一列(例如:活跃),目前为止是true/false。根据active的值,我想着色线条图。
这个线程似乎是“正确”的解决方案,但是我遇到了一个问题: seaborn or matplotlib line chart, line color depending on variable 我和OP都试图实现同样的事情:
生成的图表存在两个问题:改变颜色的线条不仅没有“连接”,而且颜色本身也“横跨”端点。
如果这样做可以更容易地生成所需的绘图。
第一个线程中有一条评论:
我有一个pandas数据帧,在其中有一列(例如:速度)我正在尝试绘制,并且还有另一列(例如:活跃),目前为止是true/false。根据active的值,我想着色线条图。
这个线程似乎是“正确”的解决方案,但是我遇到了一个问题: seaborn or matplotlib line chart, line color depending on variable 我和OP都试图实现同样的事情:
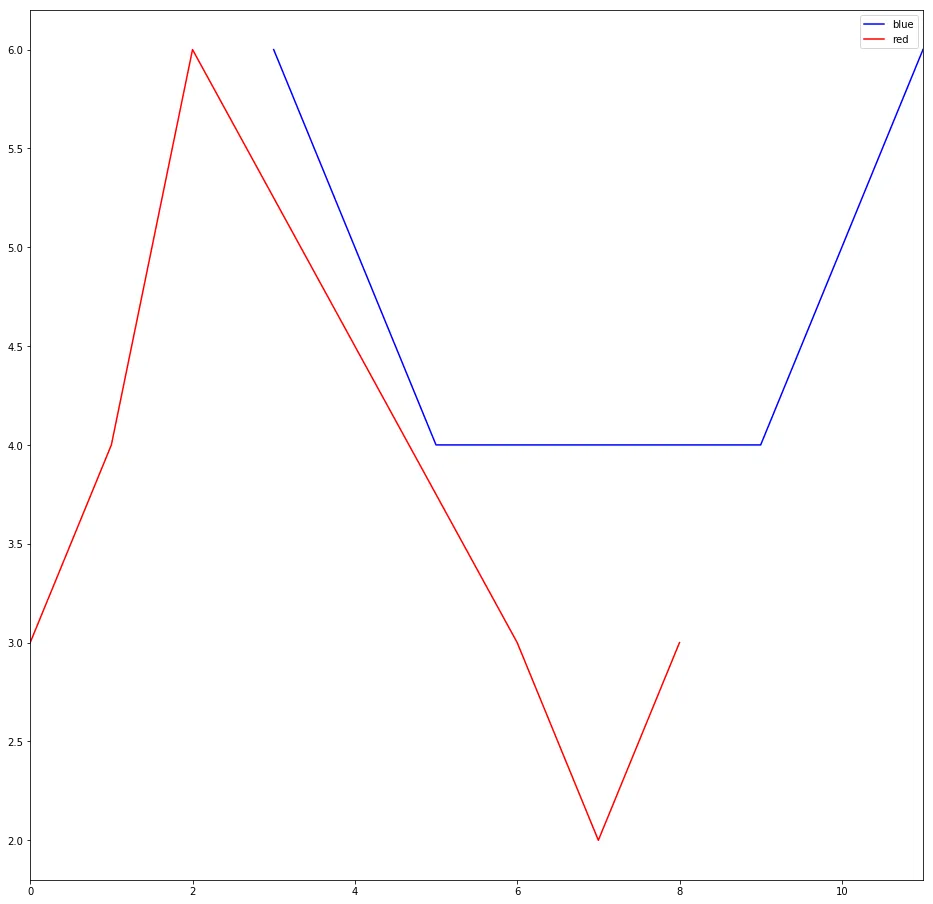
这是一个坏掉的图表/复现器:
Values=[3,4,6, 6,5,4, 3,2,3, 4,5,6]
Colors=['red','red', 'red', 'blue','blue','blue', 'red', 'red', 'red', 'blue', 'blue', 'blue']
myf = pd.DataFrame({'speed': Values, 'colors': Colors})
grouped = myf.groupby('colors')
fig, ax = plt.subplots(1)
for key, group in grouped:
group.plot(ax=ax, y="speed", label=key, color=key)
生成的图表存在两个问题:改变颜色的线条不仅没有“连接”,而且颜色本身也“横跨”端点。
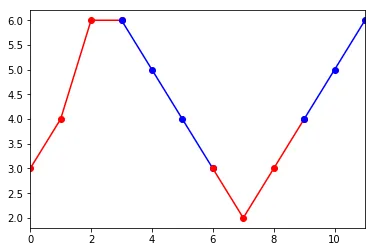
Colors=['1','1', '1', '2','2'...]
如果这样做可以更容易地生成所需的绘图。
第一个线程中有一条评论:
但我基本上是复制并粘贴了答案,所以我不确定那条评论是否完全准确。当颜色改变时,您可以通过复制点来完成,我已对答案进行了修改
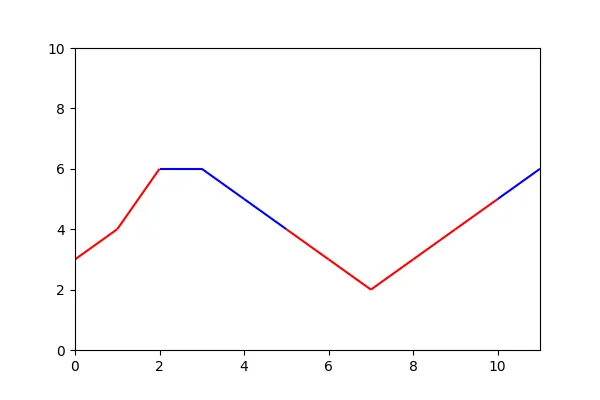
speed的数值对应于颜色。在我的特定情况下,虽然这里没有直接说明,但我是根据数据框中的另一列手动设置颜色,这就是为什么我有明确的颜色分配。这里实际的speed值并不决定颜色。 - Erik Jacobs