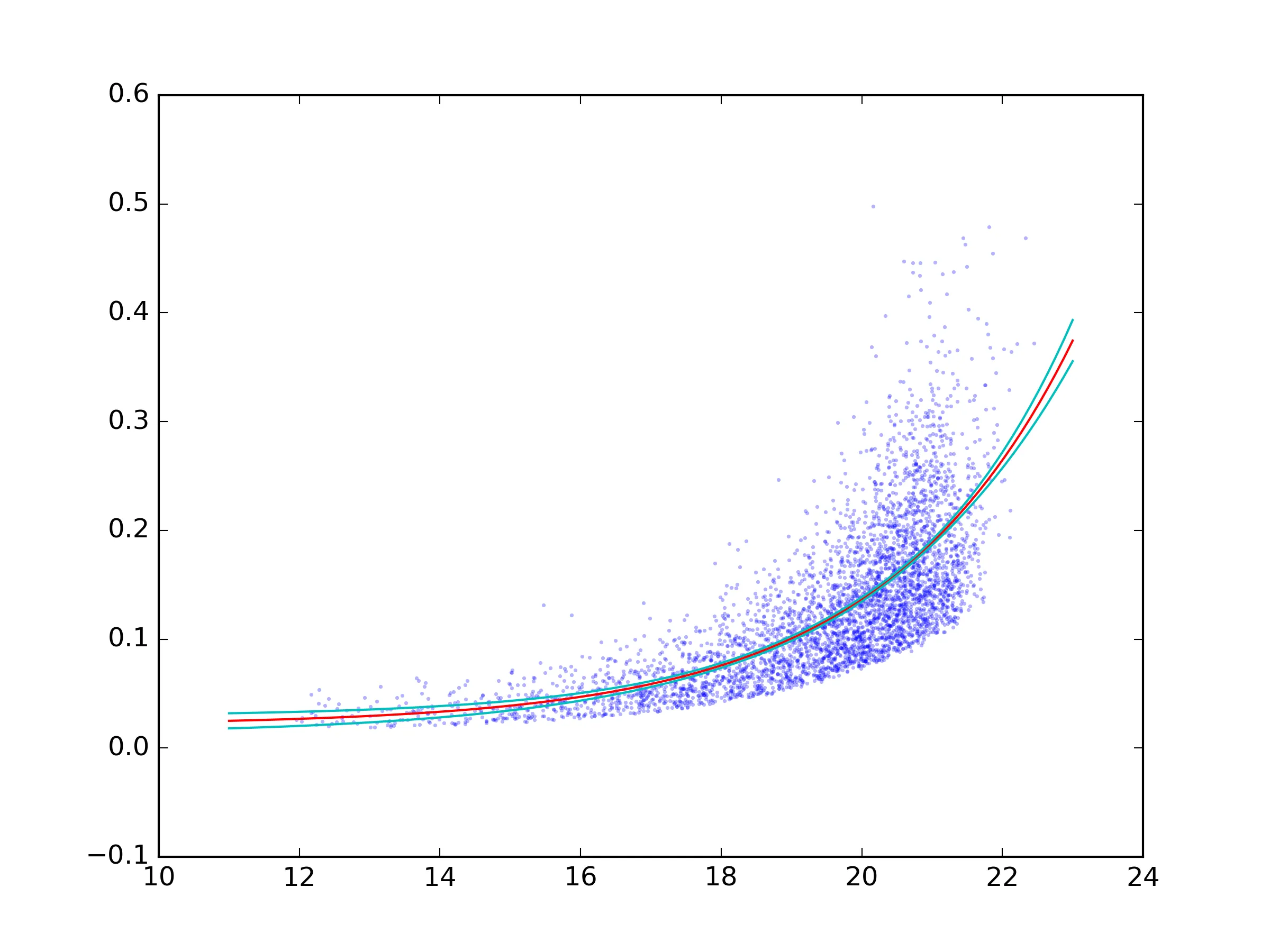
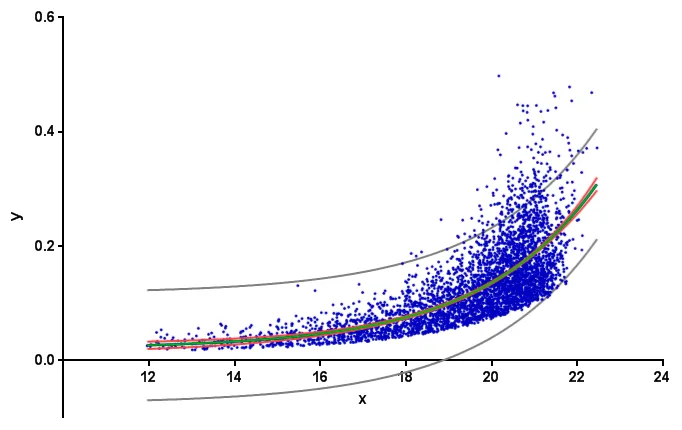
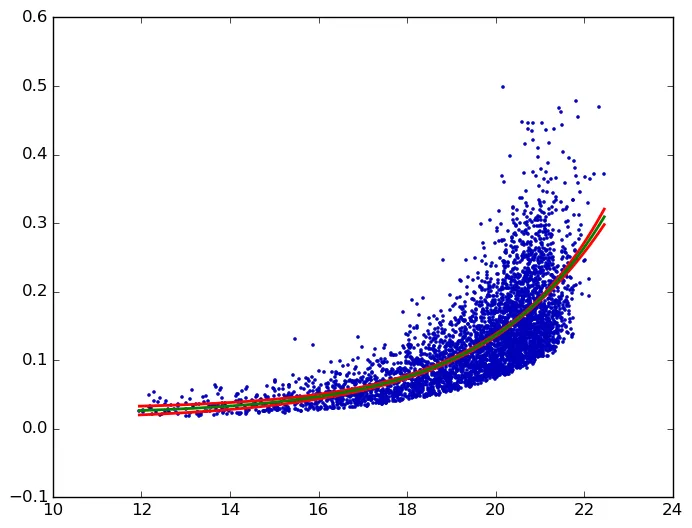
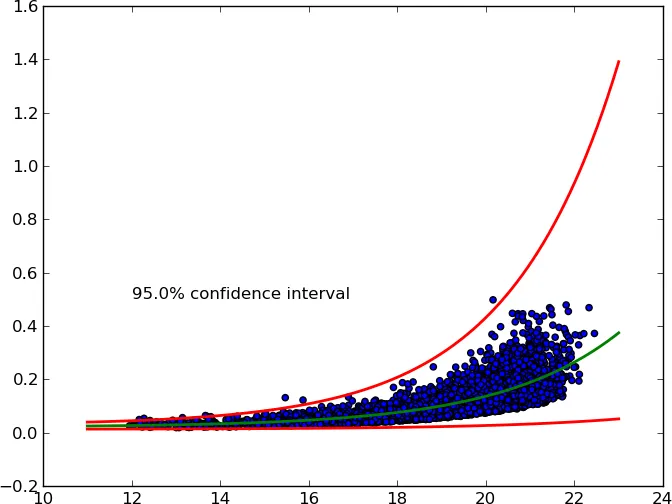
我正在尝试对一些数据(可以在此处获取)进行指数拟合的置信区间。以下是我使用的最小工作示例,以找到最佳指数拟合:
from pylab import *
from scipy.optimize import curve_fit
# Read data.
x, y = np.loadtxt('exponential_data.dat', unpack=True)
def func(x, a, b, c):
'''Exponential 3-param function.'''
return a * np.exp(b * x) + c
# Find best fit.
popt, pcov = curve_fit(func, x, y)
print popt
# Plot data and best fit curve.
scatter(x, y)
x = linspace(11, 23, 100)
plot(x, func(x, *popt), c='r')
show()
该怎样获得这个拟合的95%(或其他值)置信区间,最好使用已安装的纯Python、NumPy或SciPy包?