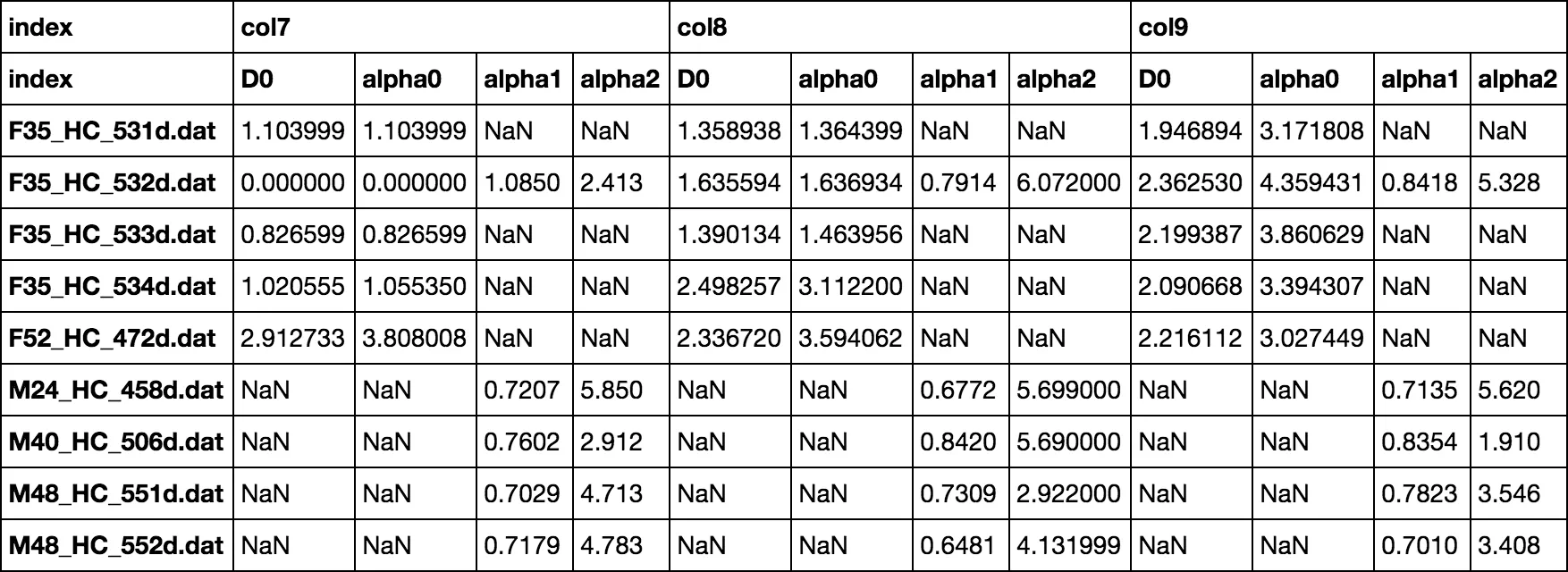
我有两个数据框 df1 和 df2:
In [56]: df1.head()
Out[56]:
col7 col8 col9
alpha0 D0 alpha0 D0 alpha0 D0
F35_HC_531d.dat 1.103999 1.103999 1.364399 1.358938 3.171808 1.946894
F35_HC_532d.dat 0.000000 0.000000 1.636934 1.635594 4.359431 2.362530
F35_HC_533d.dat 0.826599 0.826599 1.463956 1.390134 3.860629 2.199387
F35_HC_534d.dat 1.055350 1.020555 3.112200 2.498257 3.394307 2.090668
F52_HC_472d.dat 3.808008 2.912733 3.594062 2.336720 3.027449 2.216112
In [62]: df2.head()
Out[62]:
col7 col8 col9
alpha1 alpha2 alpha1 alpha2 alpha1 alpha2
filename
F35_HC_532d.dat 1.0850 2.413 0.7914 6.072000 0.8418 5.328
M48_HC_551d.dat 0.7029 4.713 0.7309 2.922000 0.7823 3.546
M24_HC_458d.dat 0.7207 5.850 0.6772 5.699000 0.7135 5.620
M48_HC_552d.dat 0.7179 4.783 0.6481 4.131999 0.7010 3.408
M40_HC_506d.dat 0.7602 2.912 0.8420 5.690000 0.8354 1.910
我想将这两个数据框连接起来。请注意,外部列名对于两个数据框都是相同的,因此我只想在一个新的数据框中看到4个子列。我尝试使用concat函数:
df = pd.concat([df1, df2], axis = 1, levels = 0)
但这会产生一个数据框,其中从 col7 到 col9 的列名会重复出现两次(因此数据框有 6 个外部列)。如何将所有列放在第一级下相同的外部列名下?