我希望能够对一个多级索引的pandas数据框进行切片。
以下是获取测试数据的代码:
import pandas as pd
testdf = {
'Name': {
0: 'H', 1: 'H', 2: 'H', 3: 'H', 4: 'H'}, 'Division': {
0: 'C', 1: 'C', 2: 'C', 3: 'C', 4: 'C'}, 'EmployeeId': {
0: 14, 1: 14, 2: 14, 3: 14, 4: 14}, 'Amt1': {
0: 124.39, 1: 186.78, 2: 127.94, 3: 258.35000000000002, 4: 284.77999999999997}, 'Amt2': {
0: 30.0, 1: 30.0, 2: 30.0, 3: 30.0, 4: 60.0}, 'Employer': {
0: 'Z', 1: 'Z', 2: 'Z', 3: 'Z', 4: 'Z'}, 'PersonId': {
0: 14, 1: 14, 2: 14, 3: 14, 4: 15}, 'Provider': {
0: 'A', 1: 'A', 2: 'A', 3: 'A', 4: 'B'}, 'Year': {
0: 2012, 1: 2012, 2: 2013, 3: 2013, 4: 2012}}
testdf = pd.DataFrame(testdf)
testdf
grouper_keys = [
'Employer',
'Year',
'Division',
'Name',
'EmployeeId',
'PersonId']
testdf2 = pd.pivot_table(data=testdf,
values='Amt1',
index=grouper_keys,
columns='Provider',
fill_value=None,
margins=False,
dropna=True,
aggfunc=('sum', 'count'),
)
print(testdf2)
给出:
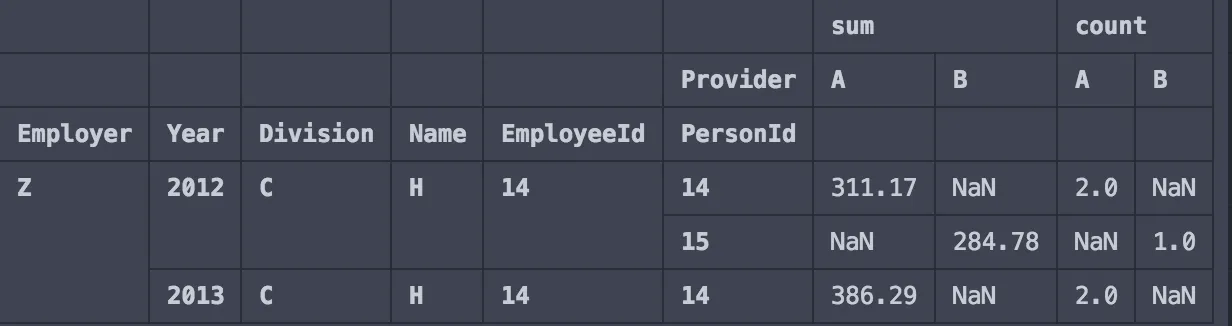
现在,我只能使用以下方式获取A或B的sum:
testdf2.loc[:, slice(None, ('sum', 'A'))]
这将会给出:
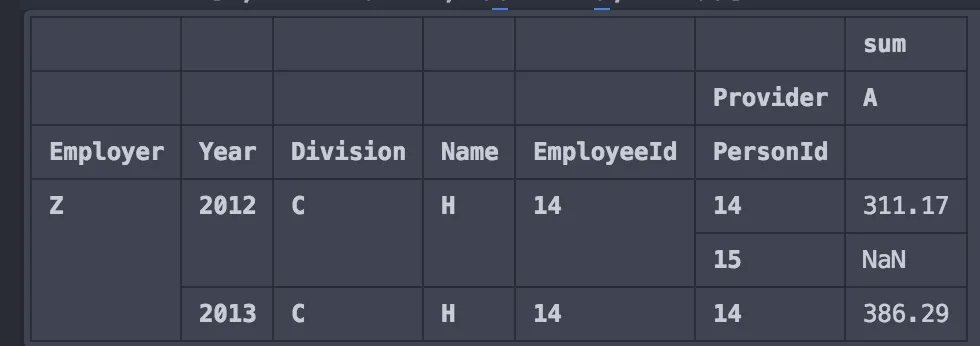
如何仅获取A或B的sum和count。
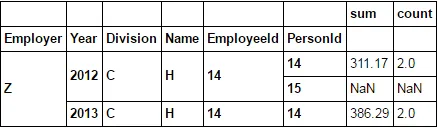
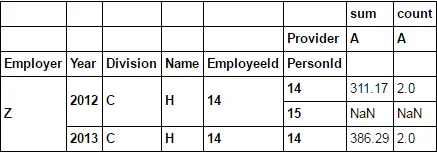
sum和count,而不是A和B。 - IanStestdf2.loc[:, idx[['sum','count'], ['A']]]看起来需要等待10分钟才能接受答案。 - muon