我知道这个情节可能会变得非常混乱,但我很想知道最有效的方法是什么。我有一个csv文件中看起来像这样的一些数据:
ROI Band Min Max Mean Stdev
1 red_2 Band 1 0.032262 0.124425 0.078073 0.028031
2 red_2 Band 2 0.021072 0.064156 0.037923 0.012178
3 red_2 Band 3 0.013404 0.066043 0.036316 0.014787
4 red_2 Band 4 0.005162 0.055781 0.015526 0.013255
5 red_3 Band 1 0.037488 0.10783 0.057892 0.018964
6 red_3 Band 2 0.02814 0.07237 0.04534 0.014507
7 red_3 Band 3 0.01496 0.112973 0.032751 0.026575
8 red_3 Band 4 0.006566 0.029133 0.018201 0.006897
9 red_4 Band 1 0.022841 0.148666 0.065844 0.0336
10 red_4 Band 2 0.018651 0.175298 0.046383 0.042339
11 red_4 Band 3 0.012256 0.045111 0.024035 0.009711
12 red_4 Band 4 0.001493 0.033822 0.014678 0.007788
13 red_5 Band 1 0.030513 0.18098 0.090056 0.044456
37 bcs_1 Band 1 0.013059 0.076753 0.037674 0.023172
38 bcs_1 Band 2 0.035227 0.08826 0.057672 0.015005
39 bcs_1 Band 3 0.005223 0.028459 0.010836 0.006003
40 bcs_1 Band 4 0.009804 0.031457 0.018094 0.007136
41 bcs_2 Band 1 0.018134 0.083854 0.040654 0.018333
42 bcs_2 Band 2 0.016123 0.088613 0.045742 0.020168
43 bcs_2 Band 3 0.008065 0.030557 0.014596 0.007435
44 bcs_2 Band 4 0.004789 0.016514 0.009815 0.003241
45 bcs_3 Band 1 0.021092 0.077993 0.037246 0.013696
46 bcs_3 Band 2 0.011918 0.068825 0.028775 0.013758
47 bcs_3 Band 3 0.003969 0.021714 0.011336 0.004964
48 bcs_3 Band 4 0.003053 0.015763 0.006283 0.002425
49 bcs_4 Band 1 0.024466 0.079989 0.049291 0.018032
50 bcs_4 Band 2 0.009274 0.093137 0.041979 0.019347
51 bcs_4 Band 3 0.006874 0.027214 0.014386 0.005386
52 bcs_4 Band 4 0.005679 0.026662 0.014529 0.006505
我希望创建一个概率密度图,其中有8条线:4条线用于“红色”四个带区间,另外4条线用于“黑色”四个带区间。目前我只能针对红色和黑色ROIs的Band 1进行操作,但我的代码输出了两张不同的图表。我已尝试使用subplot,但并没有成功。
需要帮忙吗?我知道我的方法冗长且笨拙,因此很感谢任何更聪明的解决方案!
载入包
import csv
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
files = ['example.csv']
组织数据
for f in files:
fn = f.split('.')[0]
dat = pd.read_csv(f)
df0 = dat.loc[:, ['ROI', 'Band', 'Mean']]
# parse by soil type
red = df0[df0['ROI'].str.contains("red")]
black = df0[df0['ROI'].str.contains("bcs")]
# parse by band
red.b1 = red[red['Band'].str.contains("Band 1")]
red.b2 = red[red['Band'].str.contains("Band 2")]
red.b3 = red[red['Band'].str.contains("Band 3")]
red.b4 = red[red['Band'].str.contains("Band 4")]
black.b1 = black[black['Band'].str.contains("Band 1")]
black.b2 = black[black['Band'].str.contains("Band 2")]
black.b3 = black[black['Band'].str.contains("Band 3")]
black.b4 = black[black['Band'].str.contains("Band 4")]
绘制图表
pd.DataFrame(black.b1).plot(kind="density")
pd.DataFrame(red.b1).plot(kind="density")
plt.show()
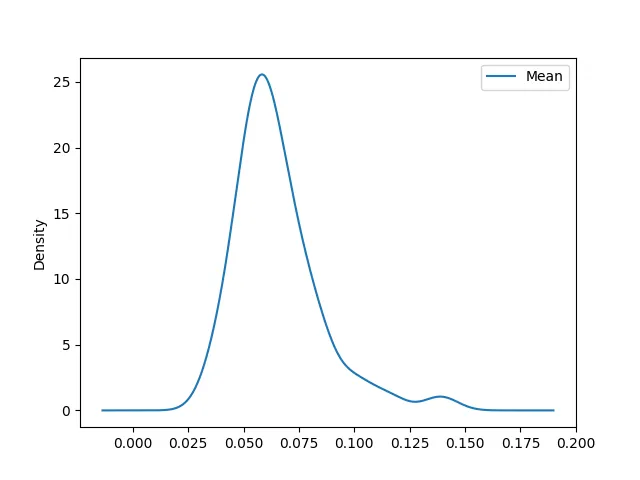
我希望这张图片上有8条线。
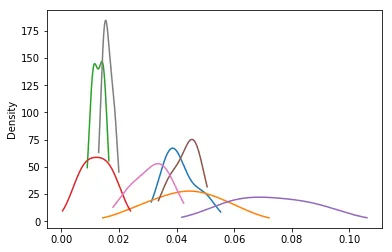
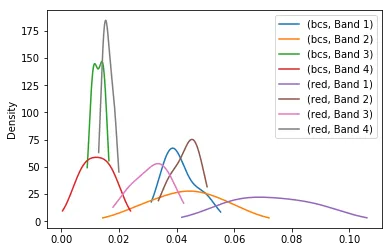
df.groupby([df.ROI.str.split('_').str[0], 'Band']).Mean.plot.kde(colormap='Accent')- piRSquared