我有一组数据集,理论上应该由二次多项式描述。我想要拟合这些数据,使用了
我不明白这一点,因此决定在我自己生成的一组数据上测试两种拟合程序:
一个示例的结果如下:
在这张图片中,
numpy.polyfit方法。但是,不幸的是,返回系数的误差不可用。因此,我决定也使用scipy.odr方法来拟合数据。奇怪的是,多项式的系数相互偏离。我不明白这一点,因此决定在我自己生成的一组数据上测试两种拟合程序:
import numpy
import scipy.odr
import matplotlib.pyplot as plt
x = numpy.arange(-20, 20, 0.1)
y = 1.8 * x**2 -2.1 * x + 0.6 + numpy.random.normal(scale = 100, size = len(x))
#Define function for scipy.odr
def fit_func(p, t):
return p[0] * t**2 + p[1] * t + p[2]
#Fit the data using numpy.polyfit
fit_np = numpy.polyfit(x, y, 2)
#Fit the data using scipy.odr
Model = scipy.odr.Model(fit_func)
Data = scipy.odr.RealData(x, y)
Odr = scipy.odr.ODR(Data, Model, [1.5, -2, 1], maxit = 10000)
output = Odr.run()
#output.pprint()
beta = output.beta
betastd = output.sd_beta
print "poly", fit_np
print "ODR", beta
plt.plot(x, y, "bo")
plt.plot(x, numpy.polyval(fit_np, x), "r--", lw = 2)
plt.plot(x, fit_func(beta, x), "g--", lw = 2)
plt.tight_layout()
plt.show()
一个示例的结果如下:
poly [ 1.77992643 -2.42753714 3.86331152]
ODR [ 3.8161735 -23.08952492 -146.76214989]
在这张图片中,
numpy.polyfit的解决方案(红色虚线)相当好。而scipy.odr的解决方案(绿色虚线)完全偏离了。我必须指出,在我要拟合的实际数据集中,numpy.polyfit和scipy.odr之间的差异较小。然而,我不明白两者之间的差异来自何处,为什么在我的测试示例中差异非常大,以及哪种拟合程序更好?我希望你能提供答案,帮助我更好地理解这两个拟合程序,并在此过程中回答我所提出的问题。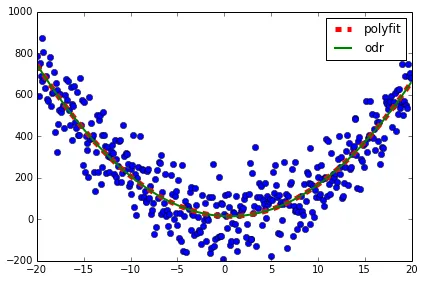
fit_type=2,我刚刚编辑了我的帖子。请再试一次。fit_type=1用于隐式拟合。 - Christian K.fit_type可能取值的不同整数的文档链接吗? - The Dude