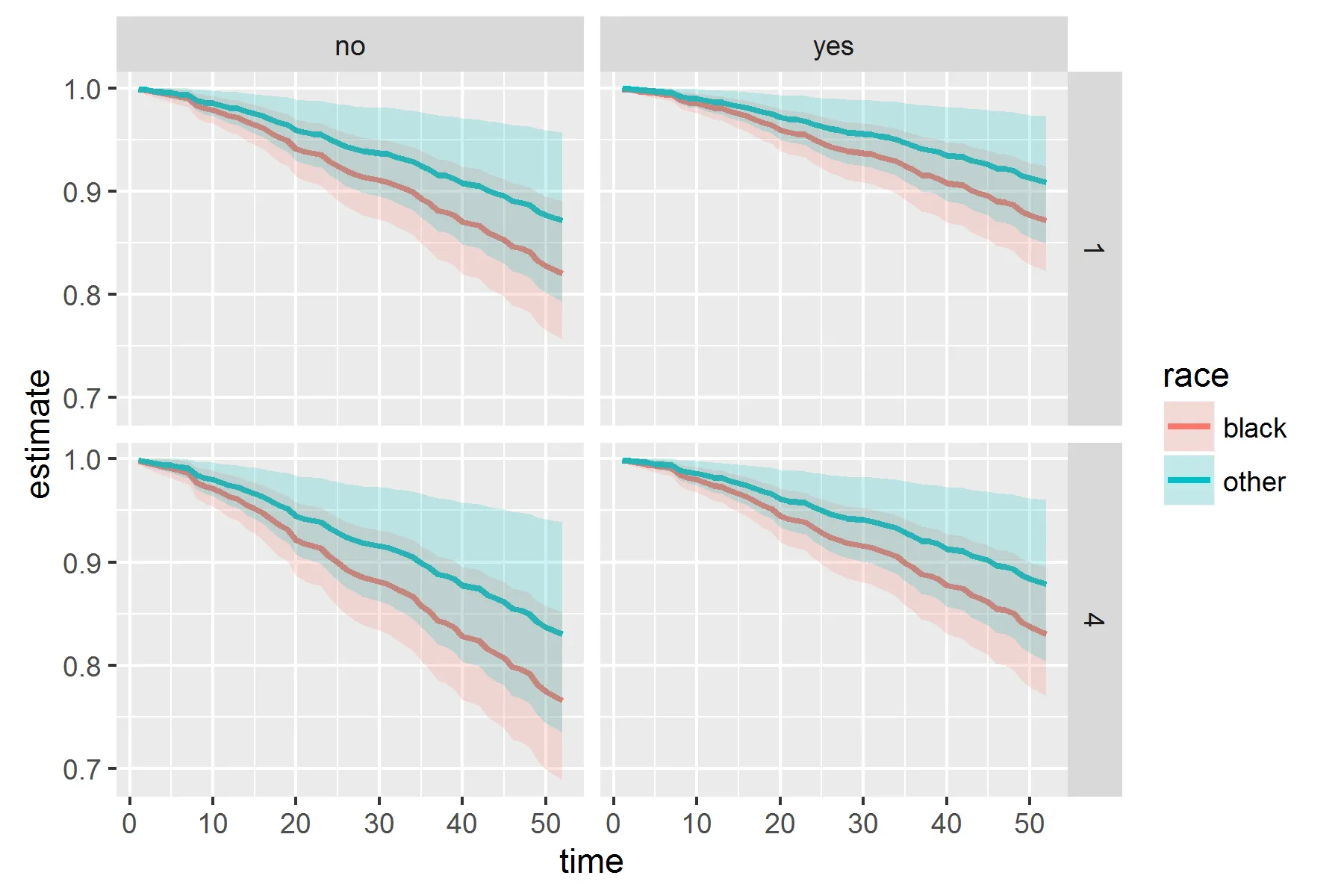
我该如何在Cox比例风险模型中为连续协变量的代表值绘制生存曲线?具体而言,我想使用“survfit.cox”、“survfit”对象在ggplot中完成此操作。
这似乎是一个已经有答案的问题,但我已经通过使用“survfit”和“newdata”等术语(以及许多其他搜索术语)搜索了SO中的所有内容。到目前为止,这个帖子最接近回答我的问题: Plot Kaplan-Meier for Cox regression 根据该帖子中一个答案提供的可重复性示例:
问题是,一旦我有了这个名为
在所有其他示例中,通常将survfit对象放入通用的
在我的数据集中,模型更加复杂,曲线也比我展示的要多得多,因此可以想象,看到40个不同的“estimate.1”..“estimate.40”变量使人难以理解哪个是哪个。
这似乎是一个已经有答案的问题,但我已经通过使用“survfit”和“newdata”等术语(以及许多其他搜索术语)搜索了SO中的所有内容。到目前为止,这个帖子最接近回答我的问题: Plot Kaplan-Meier for Cox regression 根据该帖子中一个答案提供的可重复性示例:
url <- "http://socserv.mcmaster.ca/jfox/Books/Companion/data/Rossi.txt"
df <- read.table(url, header = TRUE)
library(dplyr)
library(ggplot2)
library(survival)
library(magrittr)
library(broom)
# Identifying the 25th and 75th percentiles for prio (continuous covariate)
summary(df$prio)
# Cox proportional hazards model with other covariates
# 'prio' is our explanatory variable of interest
m1 <- coxph(Surv(week, arrest) ~
fin + age + race + prio,
data = df)
# Creating new df to get survival predictions
# Want separate curves for the the different 'fin' and 'race'
# groups as well as the 25th and 75th percentile of prio
newdf <- df %$%
expand.grid(fin = levels(fin),
age = 30,
race = levels(race),
prio = c(1,4))
# Obtain the fitted survival curve, then tidy
# into a dataframe that can be used in ggplot
survcurv <- survfit(m1, newdata = newdf) %>%
tidy()
问题是,一旦我有了这个名为
survcurv的数据框,我无法确定哪个“estimate”变量属于哪个模式,因为没有保留任何原始变量。例如,“estimate”变量中的哪一个代表了30岁、种族='其他'、prio='4'、fin='no'的拟合曲线?在所有其他示例中,通常将survfit对象放入通用的
plot()函数中,并不添加图例。我想使用ggplot为每个预测曲线添加图例。在我的数据集中,模型更加复杂,曲线也比我展示的要多得多,因此可以想象,看到40个不同的“estimate.1”..“estimate.40”变量使人难以理解哪个是哪个。