我在R中使用以下代码设置了一个Cox比例风险模型,用于预测死亡率。变量A、B和C仅被添加以避免混淆(例如年龄、性别、种族),但我们真正感兴趣的是预测因子X。X是一个连续变量。
cox.model <- coxph(Surv(time, dead) ~ A + B + C + X, data = df)
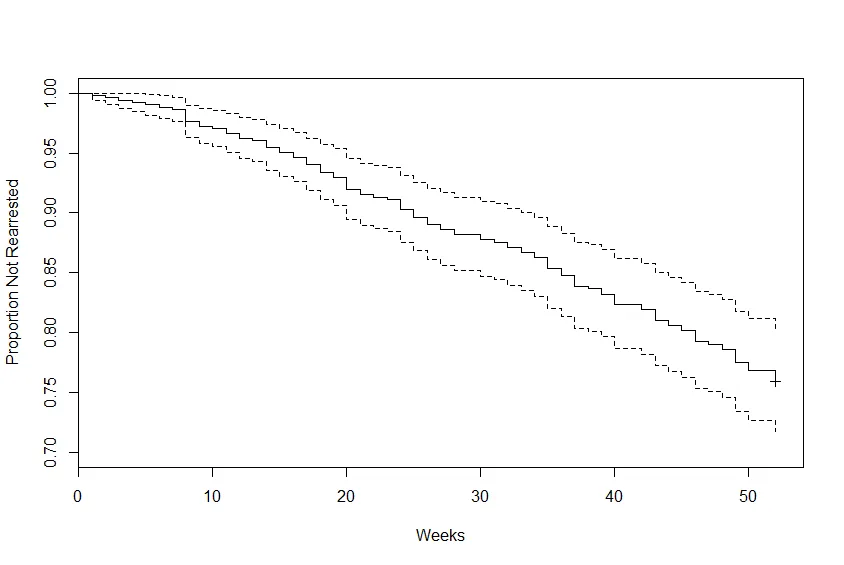
现在,我在绘制Kaplan-Meier曲线方面遇到了麻烦。我一直在寻找如何创建此图形的方法,但是我没有太多的运气。我不确定是否可以为Cox模型绘制Kaplan-Meier曲线? Kaplan-Meier是否会调整我的协变量或者它不需要它们?
我尝试过以下方法,但被告知这是不正确的。
plot(survfit(cox.model), xlab = 'Time (years)', ylab = 'Survival Probabilities')
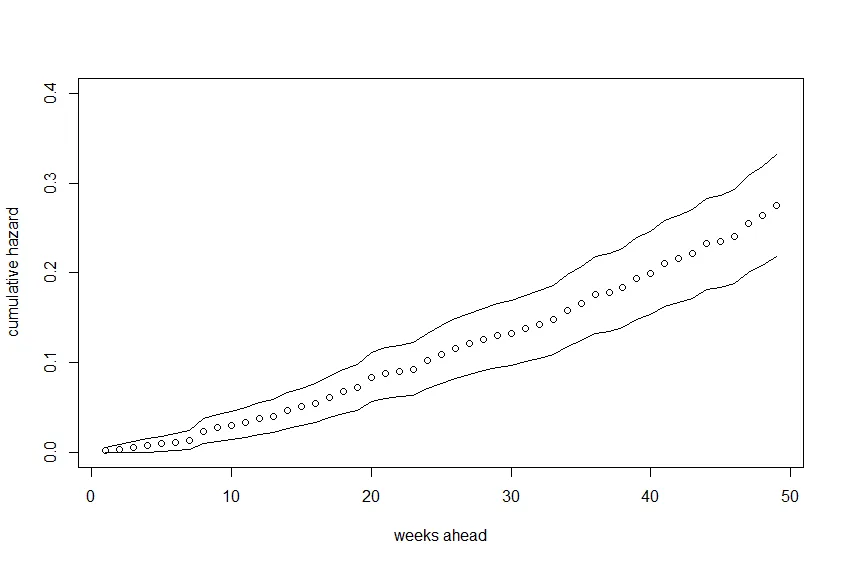
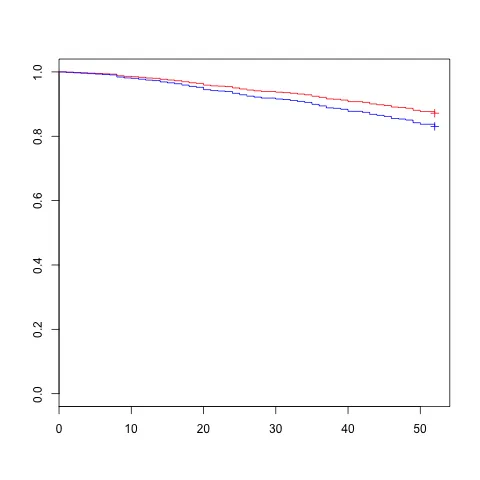
我也尝试绘制一个显示累计死亡风险的图表。我不知道自己是否做得正确,因为我试过几种不同的方法并得到了不同的结果。理想情况下,我想绘制两条线,一条显示X的第75个百分位数的死亡风险,另一条显示第25个百分位数的死亡风险。我该怎么做?
我可以列出我尝试过的所有其他方法,但我不想让任何人感到困惑!
非常感谢。