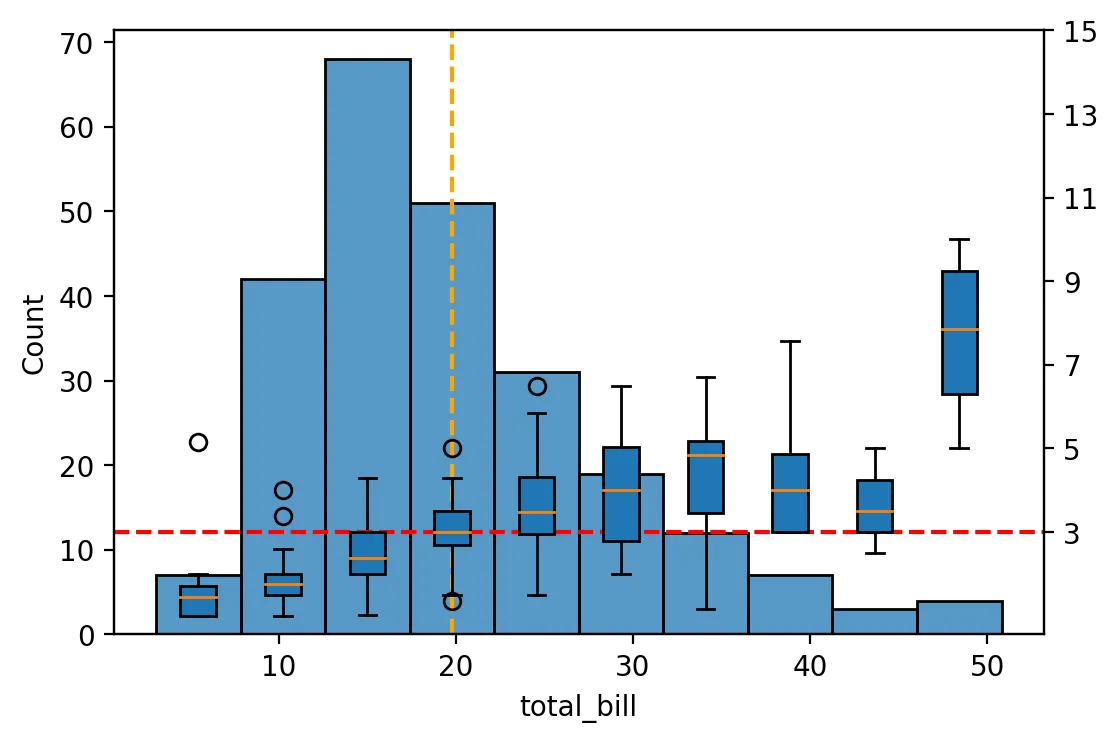
以数据集“tip”为例,我试图表示变量“total_bill”的分布,并将其各个区间与相应关联的变量“tip”的分布联系起来。在这个例子中,这张图旨在回答问题:“顾客支付账单后留下的小费分布如何?”
我已经达到了我想获得的图表(但有一个问题,在最后我会解释一下)。我采取的步骤是:
我已经达到了我想获得的图表(但有一个问题,在最后我会解释一下)。我采取的步骤是:
Dividing 'total_bill' into bins.
tips['bins_total_bill'] = pd.cut(tips.total_bill, 10) tips.head()total_bill tip smoker day time size bins_total_bill 16.99 1.01 No Sun Dinner 2 (12.618, 17.392] 10.34 1.66 No Sun Dinner 3 (7.844, 12.618] 21.01 3.50 No Sun Dinner 3 (17.392, 22.166] 23.68 3.31 No Sun Dinner 2 (22.166, 26.94] 24.59 3.61 No Sun Dinner 4 (22.166, 26.94] Creation of a pd.Series with:
Index: pd.interval of total_cost bins
Values: n° of occurrencess = tips['bins_total_bill'].value_counts(sort=False) s
(3.022, 7.844] 7
(7.844, 12.618] 42
(12.618, 17.392] 68
(17.392, 22.166] 51
(22.166, 26.94] 31
(26.94, 31.714] 19
(31.714, 36.488] 12
(36.488, 41.262] 7
(41.262, 46.036] 3
(46.036, 50.81] 4
Name: bins_total_bill, dtype: int64
Combine barplot and poxplot together
fig, ax1 = plt.subplots(dpi=200) ax2 = ax1.twinx() sns.barplot(ax=ax1, x = s.index, y = s.values) sns.boxplot(ax=ax2, x='bins_total_bill', y='tip', data=tips) sns.stripplot(ax=ax2, x='bins_total_bill', y='tip', data=tips, size=5, color="yellow", edgecolor='red', linewidth=0.3) #Title and axis labels ax1.tick_params(axis='x', rotation=90) ax1.set_ylabel('Number of bills') ax2.set_ylabel('Tips [$]') ax1.set_xlabel("Mid value of total_bill bins [$]") ax1.set_title("Tips ~ Total_bill distribution") #Reference lines average(tip) + add yticks + Legend avg_tip = np.mean(tips.tip) ax2.axhline(y=avg_tip, color='red', linestyle="--", label="avg tip") ax2.set_yticks(list(ax2.get_yticks() + avg_tip)) ax2.legend(loc='best') #Set labels axis x ax1.set_xticklabels(list(map(lambda s: round(s.mid,2), s.index)))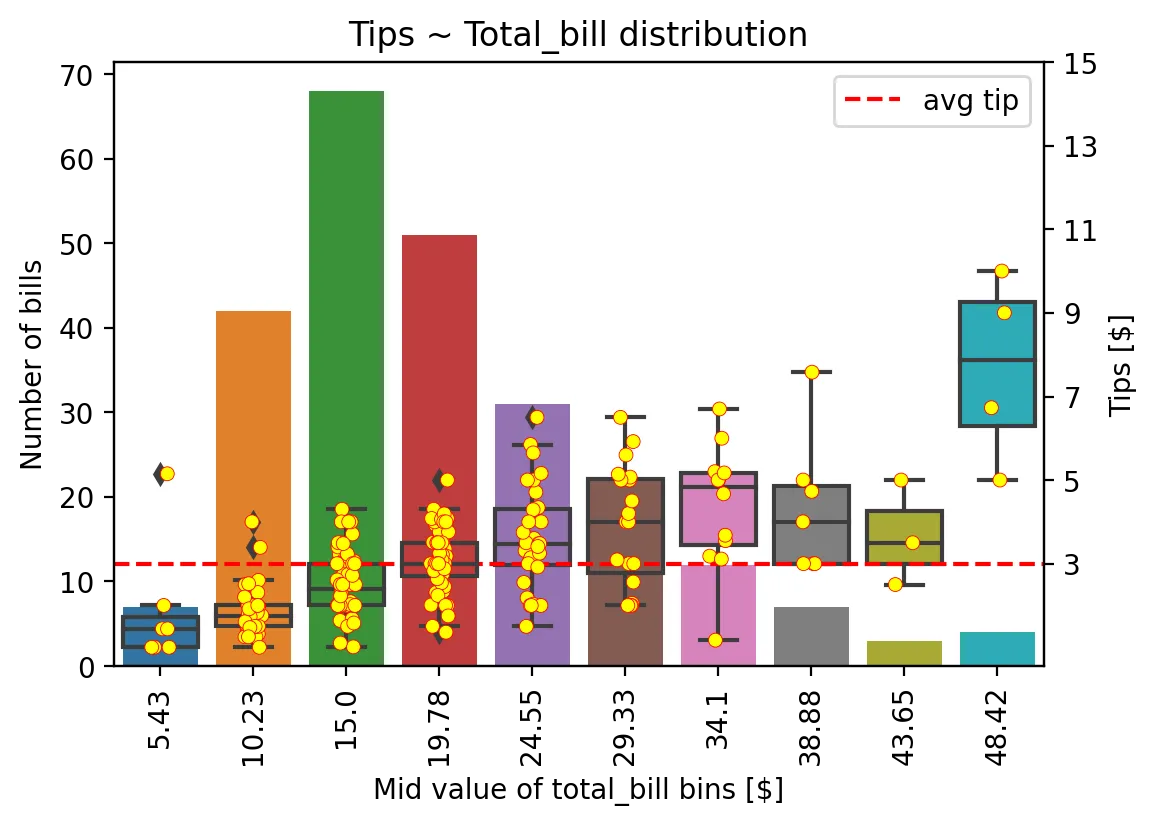
不得不说,这个图表存在问题!由于 x 轴是分类的,例如我不能在 "total_bill" 的平均值处添加一条垂直线。
我该如何修复以获得正确的结果?我也想知道是否有比我采用的方法更正确和更简化的方法。