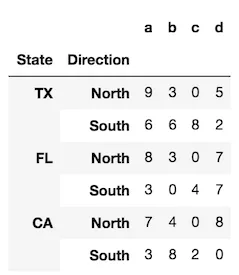
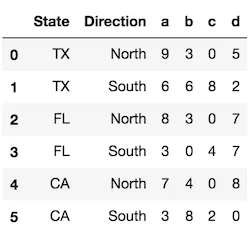
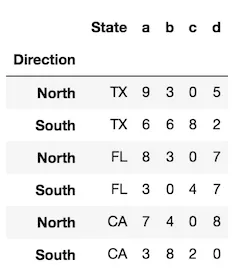
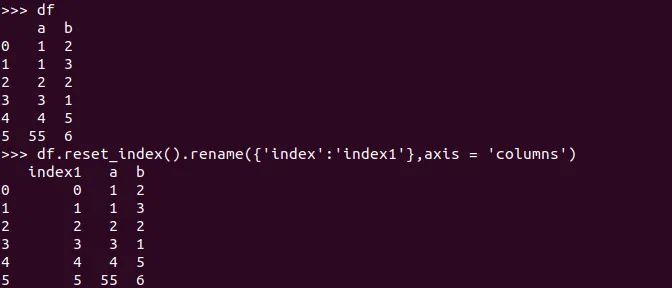
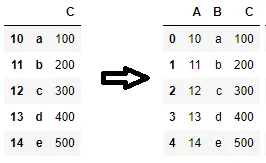
如何将数据框的索引转换为列?
例如:
例如:
gi ptt_loc
0 384444683 593
1 384444684 594
2 384444686 596
到
index1 gi ptt_loc
0 0 384444683 593
1 1 384444684 594
2 2 384444686 596