使用百分位数的问题在于,被识别为异常值的数据点取决于你的样本大小。
有很多方法可以检测异常值,你应该考虑如何对它们进行分类。理想情况下,你应该使用先验信息(例如,“任何高于/低于这个值都是不现实的,因为……”)
然而,一种常见但不太不合理的异常值测试方法是基于“中位数绝对偏差”来删除数据点。
以下是N维情况下的实现(从某篇论文代码中获取:https://github.com/joferkington/oost_paper_code/blob/master/utilities.py):
def is_outlier(points, thresh=3.5):
"""
Returns a boolean array with True if points are outliers and False
otherwise.
Parameters:
-----------
points : An numobservations by numdimensions array of observations
thresh : The modified z-score to use as a threshold. Observations with
a modified z-score (based on the median absolute deviation) greater
than this value will be classified as outliers.
Returns:
--------
mask : A numobservations-length boolean array.
References:
----------
Boris Iglewicz and David Hoaglin (1993), "Volume 16: How to Detect and
Handle Outliers", The ASQC Basic References in Quality Control:
Statistical Techniques, Edward F. Mykytka, Ph.D., Editor.
"""
if len(points.shape) == 1:
points = points[:,None]
median = np.median(points, axis=0)
diff = np.sum((points - median)**2, axis=-1)
diff = np.sqrt(diff)
med_abs_deviation = np.median(diff)
modified_z_score = 0.6745 * diff / med_abs_deviation
return modified_z_score > thresh
这与我之前的一个回答非常相似(链接),但我想详细说明样本量效应。
让我们比较一种基于百分位数的异常值检测方法(类似于@CTZhu的回答),以及用于各种不同样本大小的中位数绝对偏差(MAD)检测方法:
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
def main():
for num in [10, 50, 100, 1000]:
x = np.random.normal(0, 0.5, num-3)
x = np.r_[x, -3, -10, 12]
plot(x)
plt.show()
def mad_based_outlier(points, thresh=3.5):
if len(points.shape) == 1:
points = points[:,None]
median = np.median(points, axis=0)
diff = np.sum((points - median)**2, axis=-1)
diff = np.sqrt(diff)
med_abs_deviation = np.median(diff)
modified_z_score = 0.6745 * diff / med_abs_deviation
return modified_z_score > thresh
def percentile_based_outlier(data, threshold=95):
diff = (100 - threshold) / 2.0
minval, maxval = np.percentile(data, [diff, 100 - diff])
return (data < minval) | (data > maxval)
def plot(x):
fig, axes = plt.subplots(nrows=2)
for ax, func in zip(axes, [percentile_based_outlier, mad_based_outlier]):
sns.distplot(x, ax=ax, rug=True, hist=False)
outliers = x[func(x)]
ax.plot(outliers, np.zeros_like(outliers), 'ro', clip_on=False)
kwargs = dict(y=0.95, x=0.05, ha='left', va='top')
axes[0].set_title('Percentile-based Outliers', **kwargs)
axes[1].set_title('MAD-based Outliers', **kwargs)
fig.suptitle('Comparing Outlier Tests with n={}'.format(len(x)), size=14)
main()
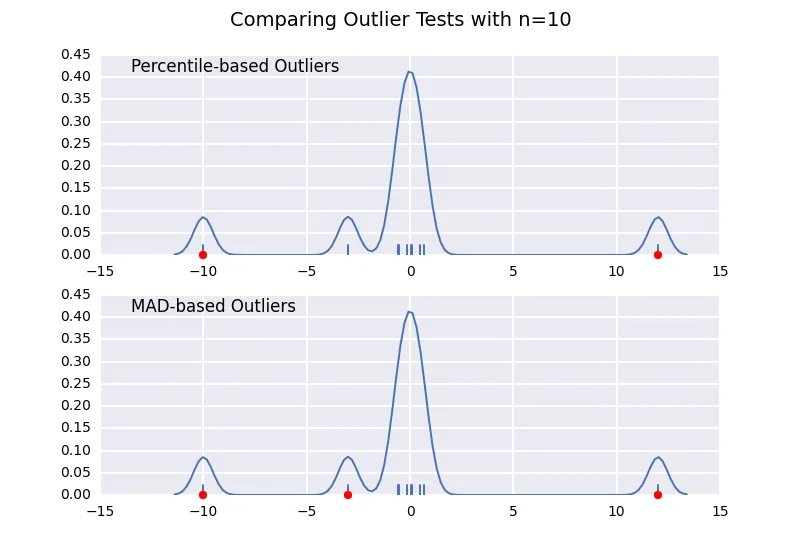
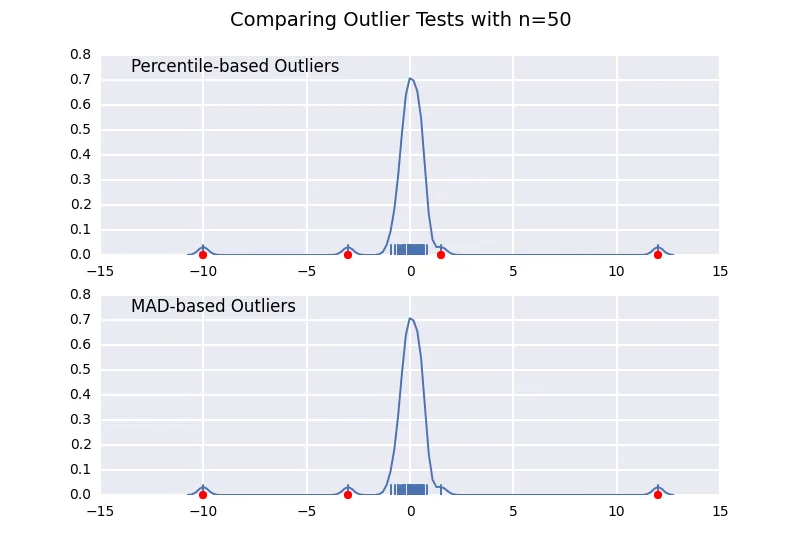
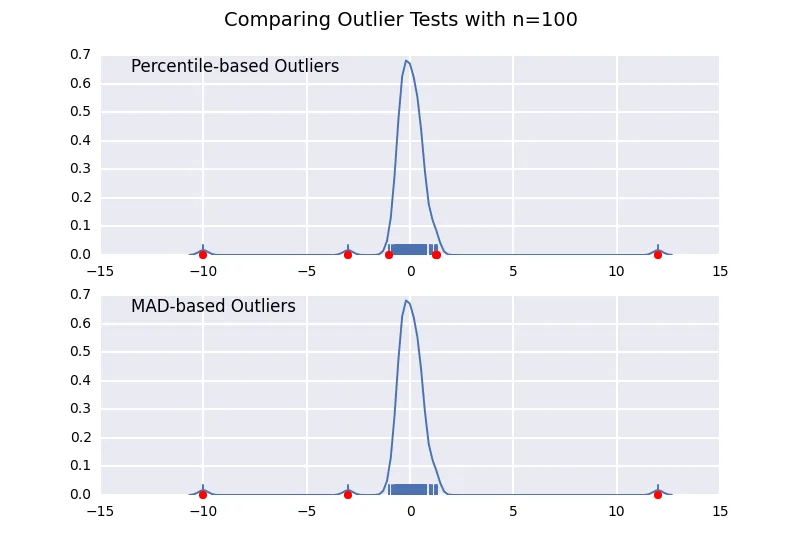
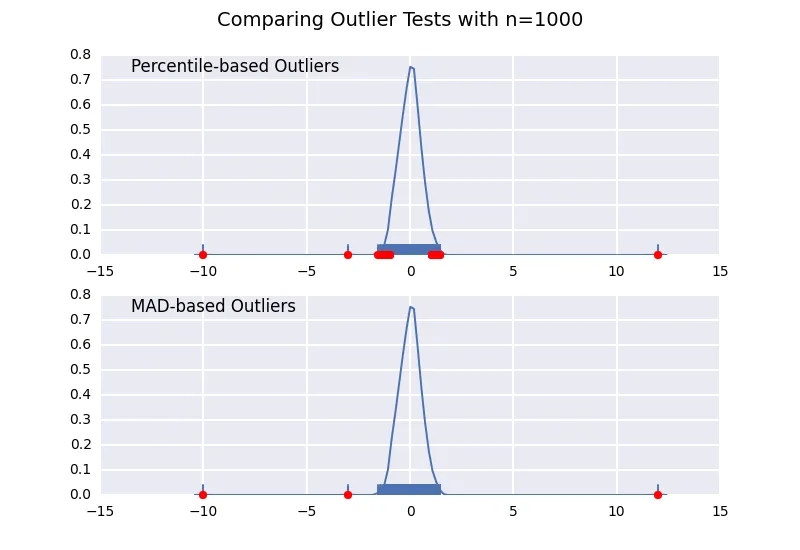
请注意,基于MAD的分类器可以正确地处理各种样本大小,而基于百分位数的分类器会将更多的数据点归类为异常值,无论它们是否真正是异常值,且随着样本大小的增加而增加。