我有来自三个完全不同的传感器源的时间序列数据,存储在CSV文件中,并希望将它们合并成一个大的CSV文件。
我已经使用numpy的genfromtxt将它们读入了numpy数组,但是我不确定下一步该做什么。
基本上,我手头的情况是这样的:
表1:
timestamp val_a val_b val_c
表格2:
timestamp val_d val_e val_f val_g
表格 3:
timestamp val_h val_i
所有时间戳均为UNIX毫秒级时间戳,数据类型为numpy.uint64。
我的要求是:
timestamp val_a val_b val_c val_d val_e val_f val_g val_h val_i
...其中所有数据按时间戳组合并排序。这三个表格中的每一个都已经按时间戳排序。 由于数据来自不同的来源,不能保证一张表格中的时间戳也出现在另外两张表格中,反之亦然。这种情况下,空缺值应该标记为N/A。
到目前为止,我尝试使用Pandas将数据转换如下:
df_sensor1 = pd.DataFrame(numpy_arr_sens1)
df_sensor2 = pd.DataFrame(numpy_arr_sens2)
df_sensor3 = pd.DataFrame(numpy_arr_sens3)
我尝试使用pandas.DataFrame.merge,但我相当确定那对我现在想做的事情行不通。有人能指点我一下吗?
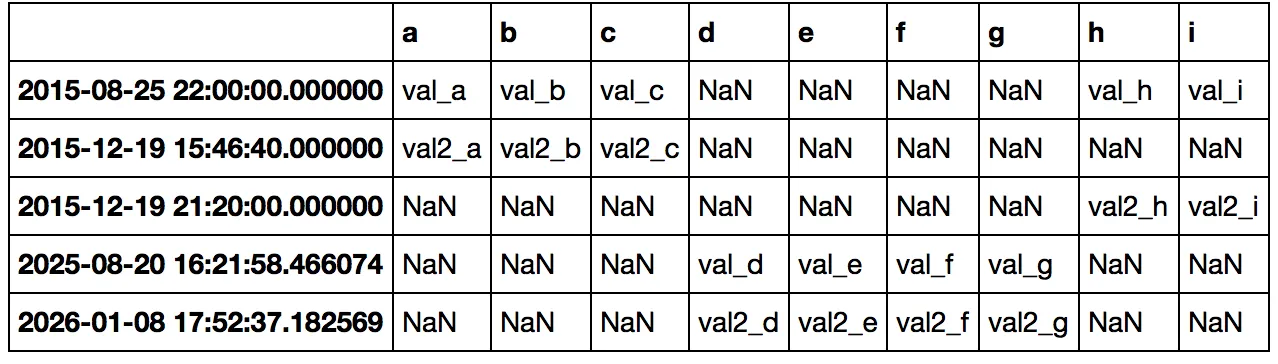
merge的代码吗?例如,如果你执行了merged = pd.merge(df_sensor1, df_sensor_2, on='timestamp'),然后对df_seonsor3重复操作,或者如果你在所有数据框上都将索引设置为时间戳,那么你只需要执行pd.concat([df_sensor_1, df_seonsor2, df_sensor3])。 - EdChummerge,但是它似乎只执行内连接,因此只有在所有表中都有时间戳的数据点才会被写入合并后的表中。我也尝试过外连接,虽然包含了所有数据,但排序也不正确。不过我刚刚尝试了concat。我执行了merged = pd.concat([df_sensor1, df_sensor2, df_sensor3], axis=1)和merged.to_csv('out.csv', sep=';', header=True, index=True, na_rep='N/A'),看起来已经完成了任务。我明天还需要验证一下。 - vind