考虑以下您问题的迷你版本:
from io import StringIO
from pandas import read_csv, to_datetime
threshold = 5
dtc = [['date', 'start_time']]
ixc = 'date_start_time'
df1 = read_csv(StringIO(u'''
date,start_time,employee_id,session_id
01/01/2016,02:03:00,7261824,871631182
01/01/2016,06:03:00,7261824,871631183
01/01/2016,11:01:00,7261824,871631184
01/01/2016,14:01:00,7261824,871631185
'''), parse_dates=dtc)
df2 = read_csv(StringIO(u'''
date,start_time,employee_id,session_id
01/01/2016,02:03:00,7261824,871631182
01/01/2016,06:05:00,7261824,871631183
01/01/2016,11:04:00,7261824,871631184
01/01/2016,14:10:00,7261824,871631185
'''), parse_dates=dtc)
提供
>>> df1
date_start_time employee_id session_id
0 2016-01-01 02:03:00 7261824 871631182
1 2016-01-01 06:03:00 7261824 871631183
2 2016-01-01 11:01:00 7261824 871631184
3 2016-01-01 14:01:00 7261824 871631185
>>> df2
date_start_time employee_id session_id
0 2016-01-01 02:03:00 7261824 871631182
1 2016-01-01 06:05:00 7261824 871631183
2 2016-01-01 11:04:00 7261824 871631184
3 2016-01-01 14:10:00 7261824 871631185
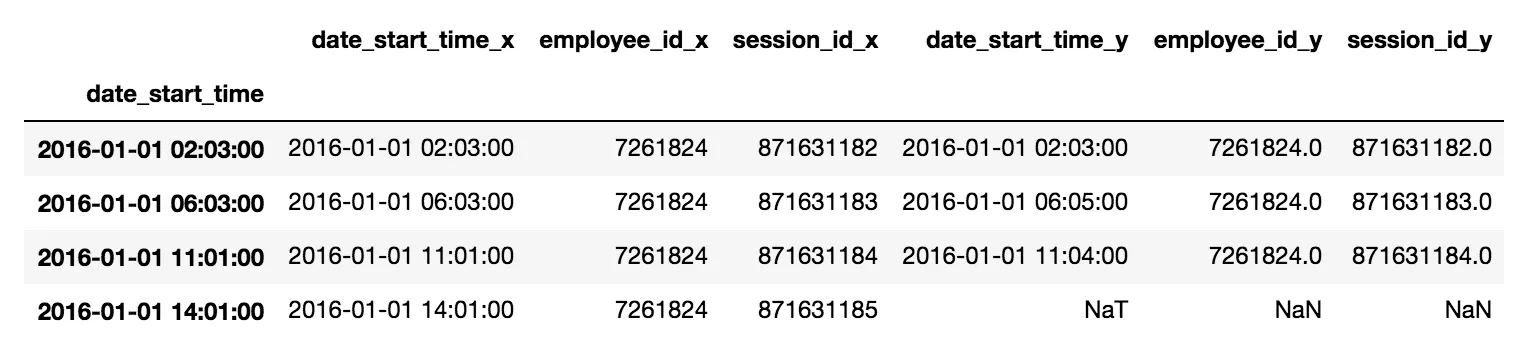
当合并时,您希望将 df2[0:3] 视为 df1[0:3] 的副本(因为它们分别相差不到5分钟),但要将 df1[3] 和 df2[3] 视为单独的会话。
解决方案1:区间匹配
这基本上就是您在编辑中建议的。您想要将两个表中的时间戳映射到以最接近5分钟舍入的时间戳为中心的10分钟间隔。
每个间隔可以通过其中点唯一表示,因此您可以在最接近5分钟的时间戳上合并数据框。例如:
import numpy as np
threshold_ns = threshold * 60 * 1e9
df1['interval'] = to_datetime(np.round(df1.date_start_time.astype(np.int64) / threshold_ns) * threshold_ns)
df2['interval'] = to_datetime(np.round(df2.date_start_time.astype(np.int64) / threshold_ns) * threshold_ns)
cols = ['interval', 'employee_id', 'session_id']
print df1.merge(df2, on=cols, how='outer')[cols]
打印
interval employee_id session_id
0 2016-01-01 02:05:00 7261824 871631182
1 2016-01-01 06:05:00 7261824 871631183
2 2016-01-01 11:00:00 7261824 871631184
3 2016-01-01 14:00:00 7261824 871631185
4 2016-01-01 11:05:00 7261824 871631184
5 2016-01-01 14:10:00 7261824 871631185
请注意,这并不完全正确。尽管它们相差只有3分钟,但会话 df1 [2] 和 df2 [2] 不被视为重复项,因为它们位于时间间隔边界的两侧。
解决方案2:一对一匹配
这是另一种方法,它依赖于以下条件:在 df1 中的会话只能在 df2 中具有零个或一个副本。
我们用与 employee_id 和 session_id 匹配且距离少于5分钟的最接近的 df2 中的时间戳替换 df1 中的时间戳。
from datetime import timedelta
def closest(row):
matches = df2.loc[(df2.employee_id == row.employee_id) &
(df2.session_id == row.session_id)]
deltas = matches.date_start_time - row.date_start_time
deltas = deltas.loc[deltas <= timedelta(minutes=threshold)]
try:
return matches.loc[deltas.idxmin()]
except ValueError:
return row
df1 = df1.apply(closest, axis=1)
cols = ['date_start_time', 'employee_id', 'session_id']
print df1.merge(df2, on=cols, how='outer')[cols]
打印
date_start_time employee_id session_id
0 2016-01-01 02:03:00 7261824 871631182
1 2016-01-01 06:05:00 7261824 871631183
2 2016-01-01 11:04:00 7261824 871631184
3 2016-01-01 14:01:00 7261824 871631185
4 2016-01-01 14:10:00 7261824 871631185
这种方法明显较慢,因为您需要每行在df1中搜索整个df2。我所编写的内容可能还可以进一步优化,但在大型数据集上仍将需要很长时间。
{kind=link}
join操作中使用类似SQL的where子句,指定一个日期,并基于另一个日期设置两个边界。如果直接在数据库中完成此操作或使用内存数据库(如SQLite)进行操作,我建议这样做。如果您在pandas中这样做,可能需要使用一些巧技,而且如果您以数据库方式实现,仍然可以将结果提取到pandas中进行交互式处理。 - ely