我有两个数据帧,它们都包含一个不规则间隔的毫秒级时间戳列。我的目标是将这些行匹配起来,以便对于每个匹配的行,1)第一个时间戳始终小于或等于第二个时间戳,2)对于满足1)条件的所有时间戳对,匹配的时间戳是最接近的。
是否有任何方法可以使用pandas.merge来实现这一点?
merge()无法执行此类连接操作,但您可以使用searchsorted():
创建一些随机时间戳:t1,t2,它们按升序排列:
import pandas as pd
import numpy as np
np.random.seed(0)
base = np.array(["2013-01-01 00:00:00"], "datetime64[ns]")
a = (np.random.rand(30)*1000000*1000).astype(np.int64)*1000000
t1 = base + a
t1.sort()
b = (np.random.rand(10)*1000000*1000).astype(np.int64)*1000000
t2 = base + b
t2.sort()
调用searchsorted()函数在t1中查找每个值在t2中的索引:
idx = np.searchsorted(t1, t2) - 1
mask = idx >= 0
df = pd.DataFrame({"t1":t1[idx][mask], "t2":t2[mask]})
这里是输出结果:
t1 t2
0 2013-01-02 06:49:13.287000 2013-01-03 16:29:15.612000
1 2013-01-05 16:33:07.211000 2013-01-05 21:42:30.332000
2 2013-01-07 04:47:24.561000 2013-01-07 04:53:53.948000
3 2013-01-07 14:26:03.376000 2013-01-07 17:01:35.722000
4 2013-01-07 14:26:03.376000 2013-01-07 18:22:13.996000
5 2013-01-07 14:26:03.376000 2013-01-07 18:33:55.497000
6 2013-01-08 02:24:54.113000 2013-01-08 12:23:40.299000
7 2013-01-08 21:39:49.366000 2013-01-09 14:03:53.689000
8 2013-01-11 08:06:36.638000 2013-01-11 13:09:08.078000
查看此结果的图表:
import pylab as pl
pl.figure(figsize=(18, 4))
pl.vlines(pd.Series(t1), 0, 1, colors="g", lw=1)
pl.vlines(df.t1, 0.3, 0.7, colors="r", lw=2)
pl.vlines(df.t2, 0.3, 0.7, colors="b", lw=2)
pl.margins(0.02)
输出:
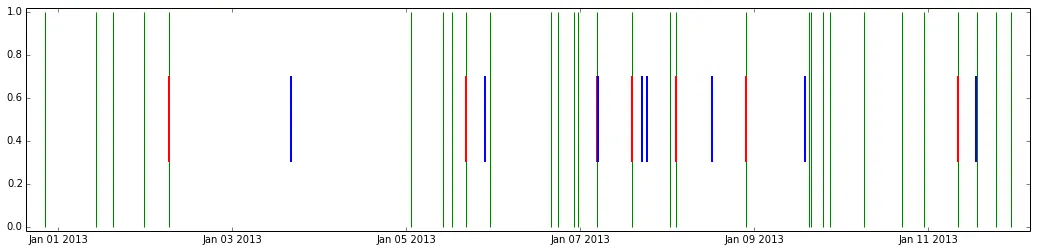
绿线代表t1,蓝线代表t2,红线是从t1中为每个t2选择的。
Pandas现在有一个名为merge_asof的函数,正好执行了被接受答案中描述的操作。
我使用了与HYRY不同的方法:
所有这些都可以写成几行代码:
df=pd.merge(df0, df1, on='Date', how='outer')
df=df.sort(['Date'], ascending=[1])
headertofill=list(df1.columns.values)
df[headertofill]=df[headertofill].fillna(method='pad')
df=df[pd.isnull(df[var_from_df0_only])==False]
# data and signal are want we want to merge
keys = ['channel', 'timestamp'] # Could be simply ['timestamp']
index = data.loc[keys].set_index(keys).index # Make index from columns to merge on
padded = signal.reindex(index, method='pad') # Key step -- reindex with filling
joined = data.join(padded, on=keys) # Join to data if needed