我希望能够在三个列(email, subject和timestamp)上合并两个数据框。由于数据框之间的时间戳不同,因此我需要为一组电子邮件和主题识别最接近的匹配时间戳。
以下是一个可复现的示例,使用了this问题中建议的查找最接近匹配的函数。
请注意,对于a@gmail.com,最接近的时间戳为10:17:39,而对于b@gmail.com,最接近的匹配是10:17:05。
结果是错误的,主要是因为最接近的日期不正确,因为它没有考虑电子邮件和主题。
期望的结果是:
以下是一个可复现的示例,使用了this问题中建议的查找最接近匹配的函数。
import numpy as np
import pandas as pd
from pandas.io.parsers import StringIO
def find_closest_date(timepoint, time_series, add_time_delta_column=True):
# takes a pd.Timestamp() instance and a pd.Series with dates in it
# calcs the delta between `timepoint` and each date in `time_series`
# returns the closest date and optionally the number of days in its time delta
deltas = np.abs(time_series - timepoint)
idx_closest_date = np.argmin(deltas)
res = {"closest_date": time_series.ix[idx_closest_date]}
idx = ['closest_date']
if add_time_delta_column:
res["closest_delta"] = deltas[idx_closest_date]
idx.append('closest_delta')
return pd.Series(res, index=idx)
a = """timestamp,email,subject
2016-07-01 10:17:00,a@gmail.com,subject3
2016-07-01 02:01:02,a@gmail.com,welcome
2016-07-01 14:45:04,a@gmail.com,subject3
2016-07-01 08:14:02,a@gmail.com,subject2
2016-07-01 16:26:35,a@gmail.com,subject4
2016-07-01 10:17:00,b@gmail.com,subject3
2016-07-01 02:01:02,b@gmail.com,welcome
2016-07-01 14:45:04,b@gmail.com,subject3
2016-07-01 08:14:02,b@gmail.com,subject2
2016-07-01 16:26:35,b@gmail.com,subject4
"""
b = """timestamp,email,subject,clicks,var1
2016-07-01 02:01:14,a@gmail.com,welcome,1,1
2016-07-01 08:15:48,a@gmail.com,subject2,2,2
2016-07-01 10:17:39,a@gmail.com,subject3,1,7
2016-07-01 14:46:01,a@gmail.com,subject3,1,2
2016-07-01 16:27:28,a@gmail.com,subject4,1,2
2016-07-01 10:17:05,b@gmail.com,subject3,0,0
2016-07-01 02:01:03,b@gmail.com,welcome,0,0
2016-07-01 14:45:05,b@gmail.com,subject3,0,0
2016-07-01 08:16:00,b@gmail.com,subject2,0,0
2016-07-01 17:00:00,b@gmail.com,subject4,0,0
"""
请注意,对于a@gmail.com,最接近的时间戳为10:17:39,而对于b@gmail.com,最接近的匹配是10:17:05。
a = """timestamp,email,subject
2016-07-01 10:17:00,a@gmail.com,subject3
2016-07-01 10:17:00,b@gmail.com,subject3
"""
b = """timestamp,email,subject,clicks,var1
2016-07-01 10:17:39,a@gmail.com,subject3,1,7
2016-07-01 10:17:05,b@gmail.com,subject3,0,0
"""
df1 = pd.read_csv(StringIO(a), parse_dates=['timestamp'])
df2 = pd.read_csv(StringIO(b), parse_dates=['timestamp'])
df1[['closest', 'time_bt_x_and_y']] = df1.timestamp.apply(find_closest_date, args=[df2.timestamp])
df1
df3 = pd.merge(df1, df2, left_on=['email','subject','closest'], right_on=['email','subject','timestamp'],how='left')
df3
timestamp_x email subject closest time_bt_x_and_y timestamp_y clicks var1
2016-07-01 10:17:00 a@gmail.com subject3 2016-07-01 10:17:05 00:00:05 NaT NaN NaN
2016-07-01 02:01:02 a@gmail.com welcome 2016-07-01 02:01:03 00:00:01 NaT NaN NaN
2016-07-01 14:45:04 a@gmail.com subject3 2016-07-01 14:45:05 00:00:01 NaT NaN NaN
2016-07-01 08:14:02 a@gmail.com subject2 2016-07-01 08:15:48 00:01:46 2016-07-01 08:15:48 2.0 2.0
2016-07-01 16:26:35 a@gmail.com subject4 2016-07-01 16:27:28 00:00:53 2016-07-01 16:27:28 1.0 2.0
2016-07-01 10:17:00 b@gmail.com subject3 2016-07-01 10:17:05 00:00:05 2016-07-01 10:17:05 0.0 0.0
2016-07-01 02:01:02 b@gmail.com welcome 2016-07-01 02:01:03 00:00:01 2016-07-01 02:01:03 0.0 0.0
2016-07-01 14:45:04 b@gmail.com subject3 2016-07-01 14:45:05 00:00:01 2016-07-01 14:45:05 0.0 0.0
2016-07-01 08:14:02 b@gmail.com subject2 2016-07-01 08:15:48 00:01:46 NaT NaN NaN
2016-07-01 16:26:35 b@gmail.com subject4 2016-07-01 16:27:28 00:00:53 NaT NaN NaN
结果是错误的,主要是因为最接近的日期不正确,因为它没有考虑电子邮件和主题。
期望的结果是:
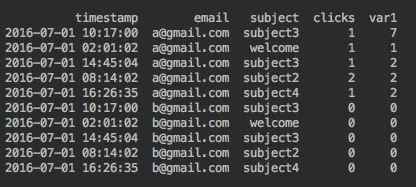
df1.groupby(['email','subject'])['timestamp'].apply(find_closest_date, args=[df1.timestamp])
但是这会导致错误,因为该函数不能用于组对象。怎么做才是最好的方法?