我为一个项目做了层次聚类分析。
我有300个观测值,每个观测值有20个变量。
我对所有变量进行了索引,使得每个变量的取值在0到1之间,越大越好。
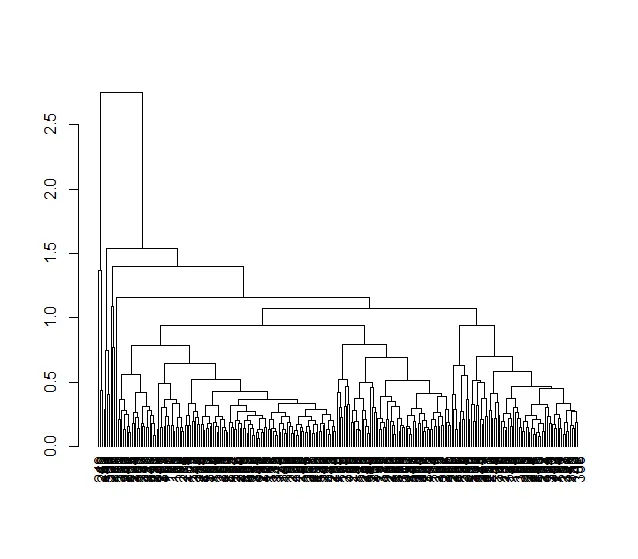
我使用以下代码创建了聚类图。
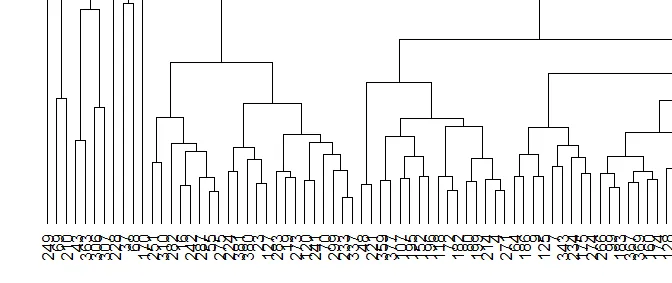
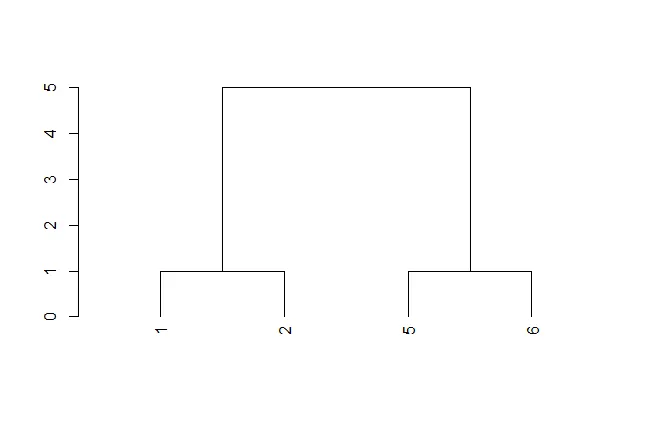
现在节点的标签是行名,从1到300的数字(见上图)。在分析过程中,我删除了数据框的第一列,它被标记为“地理”(见下图),因为它们是文本中的城市名称,会影响分析。但是我真的需要将城市名称放在聚类图中的正确位置,因为我需要根据结果选择城市列表。
我应该编写什么代码将“地理”列中的城市名称插入到此图中,对应于它们的行名?
正如您可以从数据框(下图)中看到的那样,所有城市名称都按字母顺序排列,整齐地按升序排列,就像行名一样。我相信将城市名称放在图上并不难,我只是无法通过谷歌和询问找到它。
d_data <- dist(all_data[,-1])
d_data_ind <- dist(data_ind[,-1])
hc_data_ind <- hclust(d_data_ind, method = "complete")
dend<- as.dendrogram(hc_data_ind)
plot(dend)
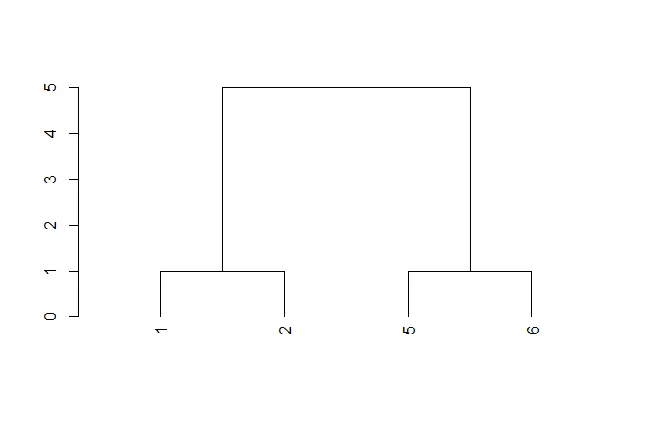
现在节点的标签是行名,从1到300的数字(见上图)。在分析过程中,我删除了数据框的第一列,它被标记为“地理”(见下图),因为它们是文本中的城市名称,会影响分析。但是我真的需要将城市名称放在聚类图中的正确位置,因为我需要根据结果选择城市列表。
我应该编写什么代码将“地理”列中的城市名称插入到此图中,对应于它们的行名?
正如您可以从数据框(下图)中看到的那样,所有城市名称都按字母顺序排列,整齐地按升序排列,就像行名一样。我相信将城市名称放在图上并不难,我只是无法通过谷歌和询问找到它。
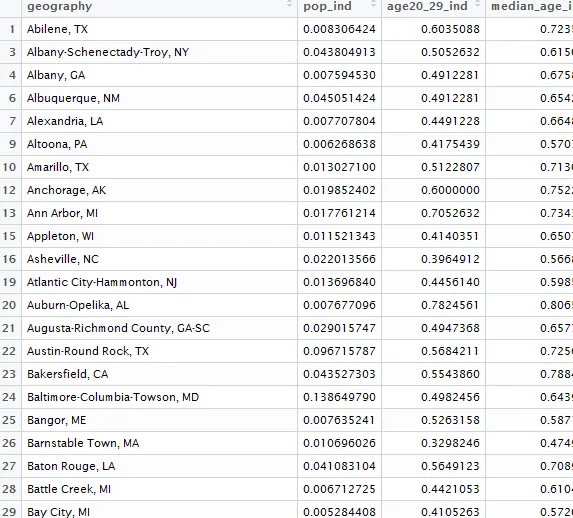

all_data,数据集的截图也不太有帮助;最好提供dput(my_data)的结果。 - lukeA