我希望您能根据分组显示小计,以便不影响总计。
这是代码:
这是代码:
import pandas as pd
import numpy as np
dict_data = [{'duration': 0.7, 'project_id': 3, 'resource': u'Arya Stark', 'activity': u'Development'},
{'duration': 0.9, 'project_id': 4, 'resource': u'Ned Stark', 'activity': u'Development'},
{'duration': 2.88, 'project_id': 7, 'resource': u'Robb Stark', 'activity': u'Development'},
{'duration': 0.22, 'project_id': 9, 'resource': u'Jon Snow', 'activity': u'Support'},
{'duration': 0.3, 'project_id': 9, 'resource': u'Jon Snow', 'activity': u'Support'},
{'duration': 2.15, 'project_id': 3, 'resource': u'Arya Stark', 'activity': u'Practise'},
{'duration': 3.35, 'project_id': 4, 'resource': u'Sansa Stark', 'activity': u'Development'},
{'duration': 2.17, 'project_id': 9, 'resource': u'Rickon Stark', 'activity': u'Development'},
{'duration': 1.03, 'project_id': 4, 'resource': u'Benjan Stark', 'activity': u'Design'},
{'duration': 1.77, 'project_id': 4, 'resource': u'Bran Stark', 'activity': u'Testing'},
{'duration': 1.17, 'project_id': 4, 'resource': u'Ned Stark', 'activity': u'Development'},
{'duration': 0.17, 'project_id': 9, 'resource': u'Jon Snow', 'activity': u'Support'},
{'duration': 1.77, 'project_id': 3, 'resource': u'catelyn stark', 'activity': u'Development'},
{'duration': 0.3, 'project_id': 9, 'resource': u'Jon Snow', 'activity': u'Support'},
{'duration': 0.45, 'project_id': 9, 'resource': u'Jon Snow', 'activity': u'Support'}]
df = pd.DataFrame(dict_data)
pvt = pd.pivot_table(df, values=['duration'],index=['project_id','resource'], columns=['activity'], aggfunc=np.sum,margins=True, fill_value=0)
所以我期望的输出如下:
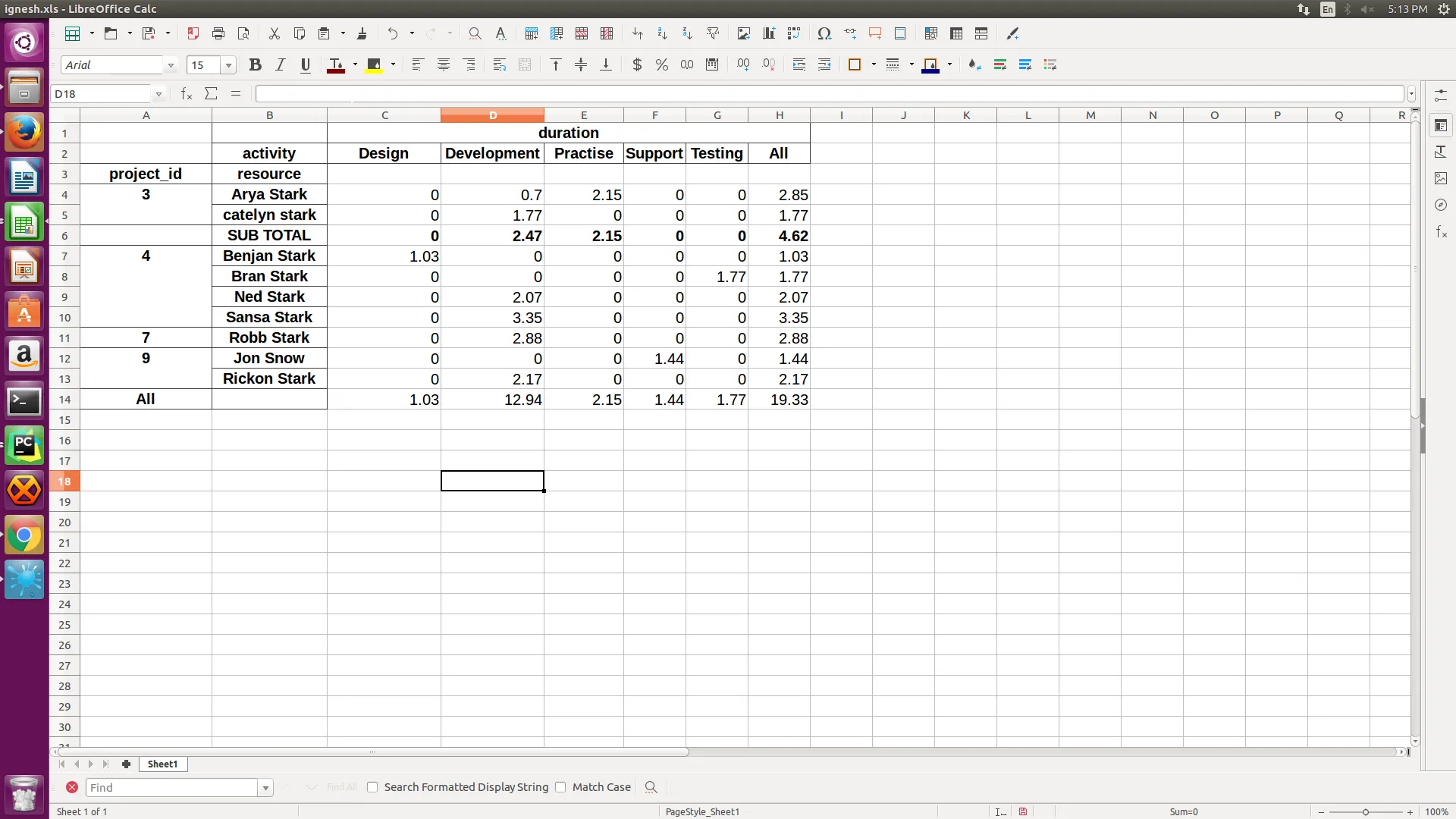
MultiIndex的第一级别中的每个组都有? - jezrael