我有以下数据:
Employee Account Currency Amount Location
Test 2 Basic USD 3000 Airport
Test 2 Net USD 2000 Airport
Test 1 Basic USD 4000 Town
Test 1 Net USD 3000 Town
Test 3 Basic GBP 5000 Town
Test 3 Net GBP 4000 Town
我可以通过以下方式成功转变:
import pandas as pd
table = pd.pivot_table(df, values=['Amount'], index=['Location', 'Employee'], columns=['Account', 'Currency'], fill_value=0, aggfunc=np.sum, dropna=True)
输出:
Amount
Account Basic Net
Currency GBP USD GBP USD
Location Employee
Airport Test 2 0 3000 0 2000
Town Test 1 0 4000 0 3000
Test 3 5000 0 4000 0
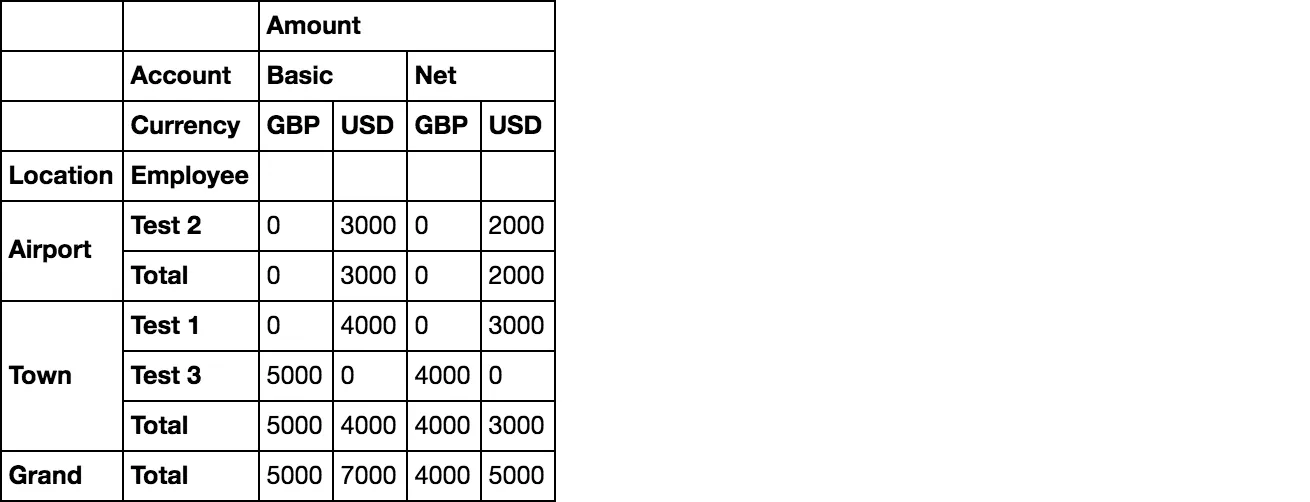
如何通过地点实现小计,然后在底部得到一个总计。
Amount
Account Basic Net
Currency GBP USD GBP USD
Location Employee
Airport Test 2 0 3000 0 2000
Airport Total 3000 0 2000
Town Test 1 0 4000 0 3000
Test 3 5000 0 4000 0
Town Total 5000 4000 4000 3000
Grand Total 5000 7000 4000 5000
我尝试按照这里的方法,但它没有给出想要的输出结果。谢谢。