我有两组数据,想要找到它们之间的相关性。虽然数据有些分散,但显然存在关系。我目前使用 numpy 的 polyfit(8阶),但线条在开始和结束处有些“抖动”,这不太合适。另外,我认为拟合在线条开始处不太好(曲线应该稍微陡峭一些)。
如何通过这些数据点获得最佳的“样条”拟合?
如何通过这些数据点获得最佳的“样条”拟合?
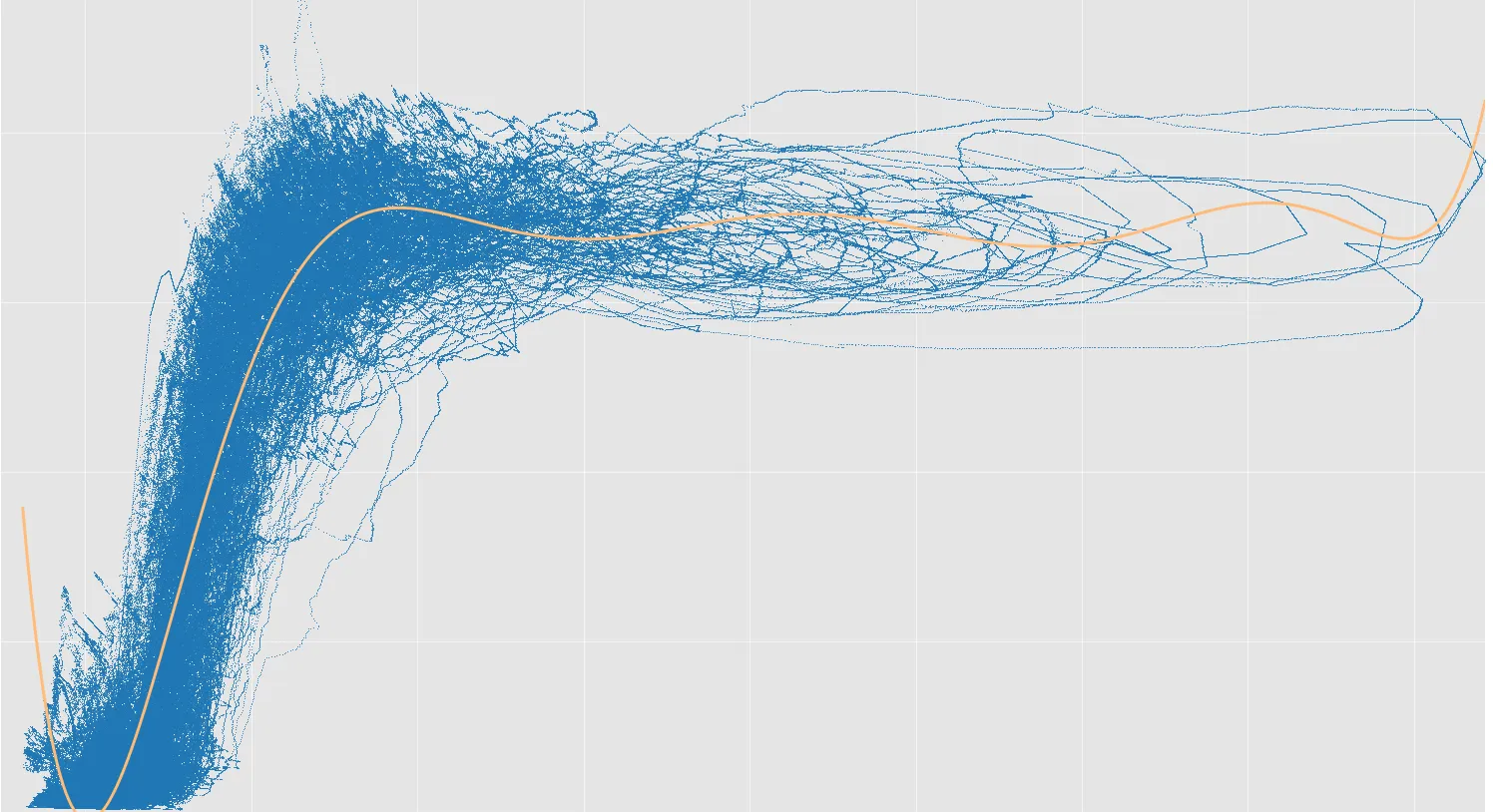
# fit regression line
regressionLineOrder = 8
regressionLine = np.polyfit(data['x'], data['y'], regressionLineOrder)
p = np.poly1d(regressionLine)