我有一个任意的输入曲线,以numpy数组的形式给出。 我想创建一个平滑版本,类似于滚动均值,但严格大于原始版本并且严格平滑。 我可以使用滚动均值,但是如果输入曲线具有负峰,则平滑版本将在该峰周围下降到原始版本以下。然后,我可以简单地使用此内容和原始内容的最大值,但这会在转换发生时引入非平滑斑点。
此外,我希望能够使用前瞻和后瞻来为此结果曲线参数化算法,因此,如果具有大前瞻和小后瞻,则生成的曲线将更倾向于下降边缘,而具有大后瞻和小前瞻,则将更接近上升边缘。
我尝试使用pandas。 系列(a).rolling()设施获得滚动平均值,滚动最大值等,但到目前为止,我找不到一种方法来生成我的输入的平滑版本,该版本在所有情况下都保持在输入之上。
我猜测有一种方法可以将滚动最大值和滚动平均值结合起来以实现我想要的效果,因此这里提供了一些计算这些的代码:
这可以通过填充左侧(pre)和右侧(post)的边缘值来为任何滚动函数做准备:
现在我们可以应用滚动平均:
计算滚动最大值,你可以使用这个:
但是仅仅使用滚动最大值在许多情况下并不平滑,并且会在原始峰值周围显示许多平顶。我更喜欢一种平滑处理这些峰值的方法。
如果您还安装了pyqtgraph,您可以轻松地绘制这样的曲线:
当然,其他绘图库也可以。
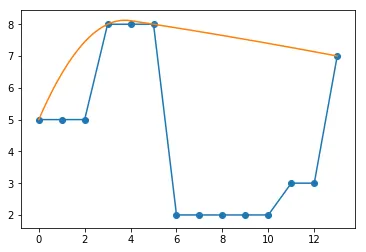
我想要的结果是一条曲线,例如由这些值形成的曲线:
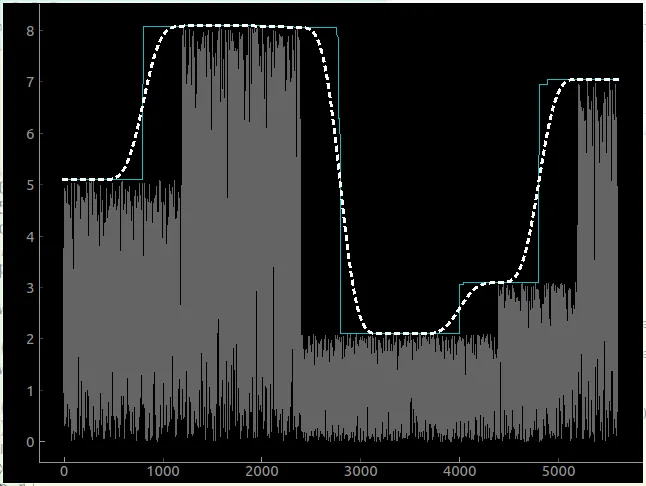
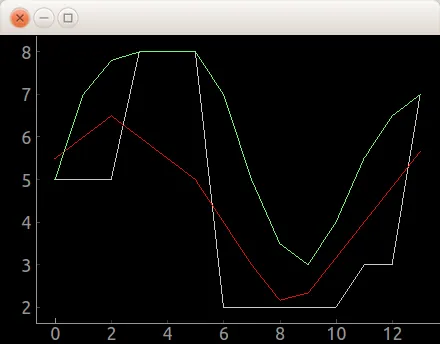
这是曲线的图像。白线是原始数据(输入),红色是滚动平均值,绿色是我想要的大致效果:
这将创建30次应用过滤器的迭代,使用pyqtplot可以绘制这些迭代的图形:
此外,我希望能够使用前瞻和后瞻来为此结果曲线参数化算法,因此,如果具有大前瞻和小后瞻,则生成的曲线将更倾向于下降边缘,而具有大后瞻和小前瞻,则将更接近上升边缘。
我尝试使用pandas。 系列(a).rolling()设施获得滚动平均值,滚动最大值等,但到目前为止,我找不到一种方法来生成我的输入的平滑版本,该版本在所有情况下都保持在输入之上。
我猜测有一种方法可以将滚动最大值和滚动平均值结合起来以实现我想要的效果,因此这里提供了一些计算这些的代码:
import pandas as pd
import numpy as np
我的输入曲线:
original = np.array([ 5, 5, 5, 8, 8, 8, 2, 2, 2, 2, 2, 3, 3, 7 ])
这可以通过填充左侧(pre)和右侧(post)的边缘值来为任何滚动函数做准备:
pre = 2
post = 3
padded = np.pad(original, (pre, post), 'edge')
现在我们可以应用滚动平均:
smoothed = pd.Series(padded).rolling(
pre + post + 1).mean().get_values()[pre+post:]
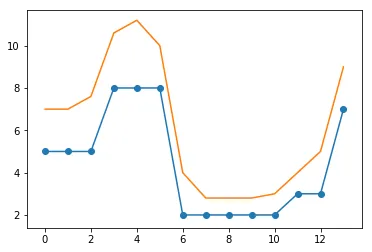
但现在平滑版本在原始版本下方,例如在索引4处:
print(original[4], smoothed[4]) # 8 and 5.5
计算滚动最大值,你可以使用这个:
maximum = pd.Series(padded).rolling(
pre + post + 1).max().get_values()[pre+post:]
但是仅仅使用滚动最大值在许多情况下并不平滑,并且会在原始峰值周围显示许多平顶。我更喜欢一种平滑处理这些峰值的方法。
如果您还安装了pyqtgraph,您可以轻松地绘制这样的曲线:
import pyqtgraph as pg
p = pg.plot(original)
p.plotItem.plot(smoothed, pen=(255,0,0))
当然,其他绘图库也可以。
我想要的结果是一条曲线,例如由这些值形成的曲线:
goal = np.array([ 5, 7, 7.8, 8, 8, 8, 7, 5, 3.5, 3, 4, 5.5, 6.5, 7 ])
这是曲线的图像。白线是原始数据(输入),红色是滚动平均值,绿色是我想要的大致效果:
编辑:我刚刚发现了一个名为peakutils的模块中的baseline()和envelope()函数。这两个函数可以计算给定度数的多项式,分别适用于输入的下峰值和上峰值。对于小样本来说,这可能是一个不错的解决方案。但如果应用于数百万个值的大样本,则需要非常高的度数,这时计算时间也相当长。将其分段处理(每段一部分)会带来一堆新的问题和难题(如如何正确拼接并保持平滑且保证在输入之上,处理大量碎片时的性能等),所以如果可能的话,我想避免这种情况。
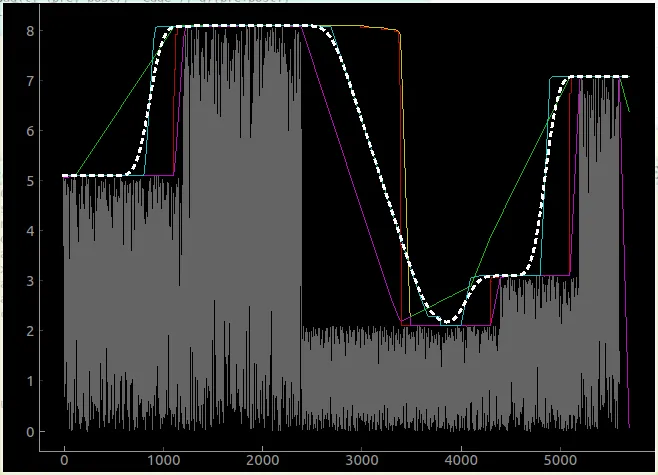
编辑2:我有一个很有前途的方法,即通过反复应用一个过滤器来创建滚动均值,稍微向左和向右移动它,然后取这两个和原始样本的最大值。经过多次应用后,它可以以我想要的方式平滑曲线。然而,在深谷中可能仍然存在一些不平滑的地方。以下是此代码:
pre = 30
post = 30
margin = 10
s = [ np.array(sum([[ x ] * 100 for x in
[ 5, 5, 5, 8, 8, 8, 2, 2, 2, 2, 2, 3, 3, 7 ]], [])) ]
for _ in range(30):
s.append(np.max([
pd.Series(np.pad(s[-1], (margin+pre, post), 'edge')).rolling(
1 + pre + post).mean().get_values()[pre+post:-margin],
pd.Series(np.pad(s[-1], (pre, post+margin), 'edge')).rolling(
1 + pre + post).mean().get_values()[pre+post+margin:],
s[-1]], 0))
这将创建30次应用过滤器的迭代,使用pyqtplot可以绘制这些迭代的图形:
p = pg.plot(original)
for q in s:
p.plotItem.plot(q, pen=(255, 100, 100))
生成的图像如下所示:
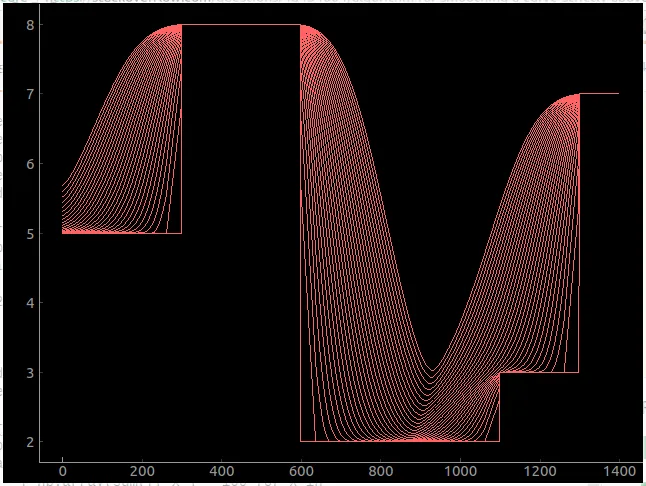
我不喜欢这种方法的两个方面:①需要重复多次(这会减慢我的速度),②在山谷部分仍然存在不平滑的部分(尽管在我的用例中可能可以接受)。