我觉得这个问题很有趣。解决方案取决于您是想绘制密度函数还是真实直方图。后者要复杂得多。这里提供了有关直方图和密度函数之间差异的更多信息。
密度函数
这将为您提供所需的密度函数:
def histedges_equalN(x, nbin):
npt = len(x)
return np.interp(np.linspace(0, npt, nbin + 1),
np.arange(npt),
np.sort(x))
x = np.random.randn(1000)
n, bins, patches = plt.hist(x, histedges_equalN(x, 10), normed=True)
请注意使用
normed=True,它指定我们正在计算和绘制密度函数。在这种情况下,区域是完全相等的(您可以通过查看
n * np.diff(bins)来检查)。还要注意,此解决方案涉及找到具有相同点数的箱子。
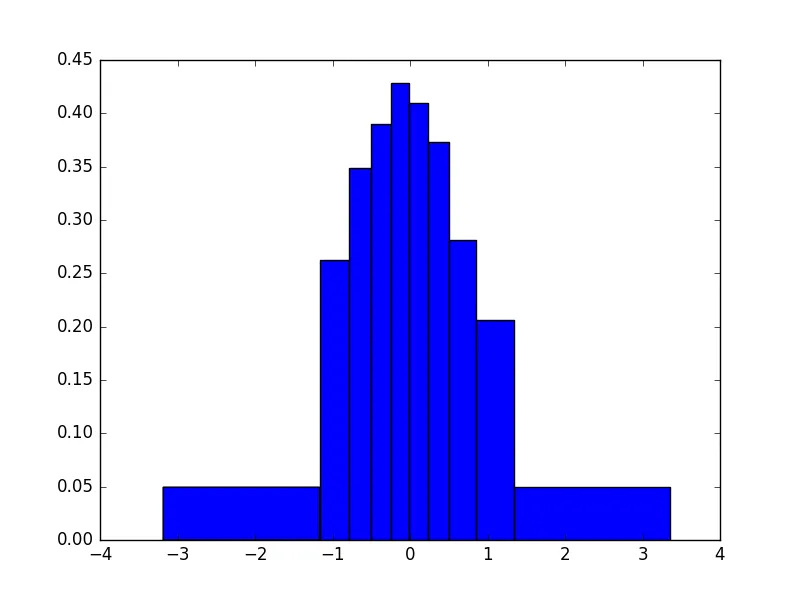
直方图
这里有一个解决方案,可以为直方图提供大致相等的面积框:
def histedges_equalA(x, nbin):
pow = 0.5
dx = np.diff(np.sort(x))
tmp = np.cumsum(dx ** pow)
tmp = np.pad(tmp, (1, 0), 'constant')
return np.interp(np.linspace(0, tmp.max(), nbin + 1),
tmp,
np.sort(x))
n, bins, patches = plt.hist(x, histedges_equalA(x, nbin), normed=False)
这些框的面积并不相等,尤其是第一个和最后一个框,它们的面积通常比其他框大约30%。这是正态分布尾部数据稀疏分布的结果,我认为只要数据集中存在稀疏的区域,这种现象就会持续存在。
顺便说一句:我尝试过改变pow的值,并发现当使用正态分布时,约为0.56的值具有较低的RMS误差。我坚持使用平方根,因为当数据紧密分布(相对于箱子宽度)时,它的表现最佳,而且我相信它有一个理论基础,但我还没去深究(有人知道吗?)。
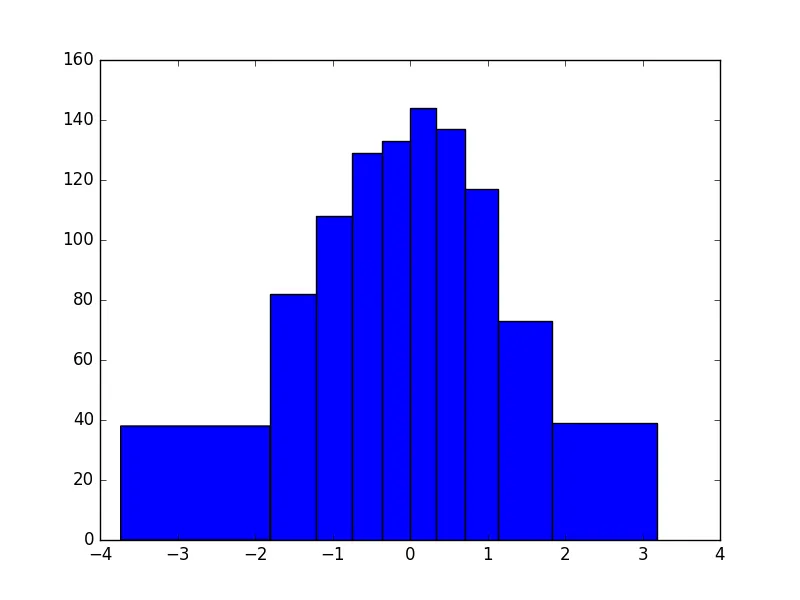
等面积直方图的问题
据我所知,这个问题无法得到精确的解决方案。这是因为它对数据的离散化非常敏感。举个例子,假设你的数据集中第一个点是-13的离群值,下一个值是-3,如下图中红色圆点所示:
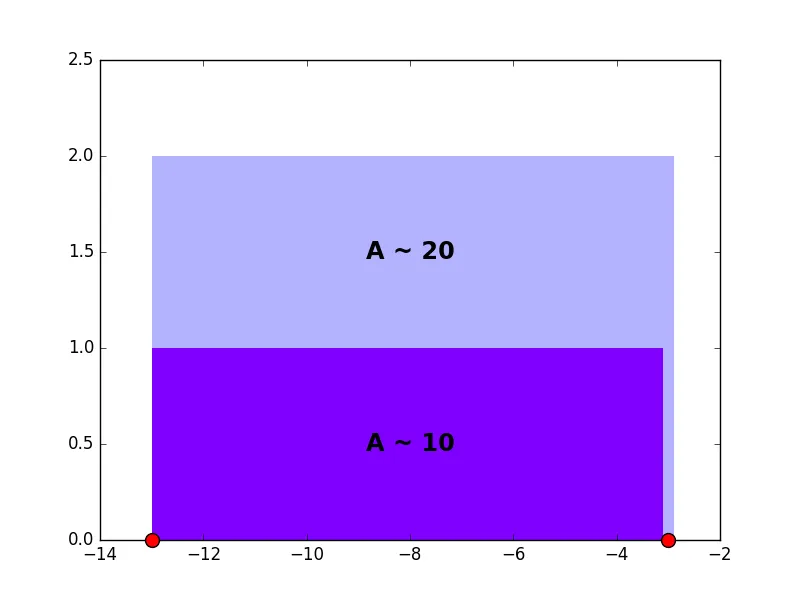
现在假设你的直方图的总“面积”为150,而你想要10个条柱。在这种情况下,每个直方图条柱的面积应该大约是15,但是你无法达到这个目标,因为一旦你的条柱包括第二个点,它的面积就会从10跳到20。也就是说,数据不允许此条柱的面积在10和20之间。解决这个问题的一个方法可能是调整箱子的下限以增加其面积,但如果这个“间隙”在数据集的中间,这种方法开始变得武断而且无效。