以下图片对我来说肯定有意义。 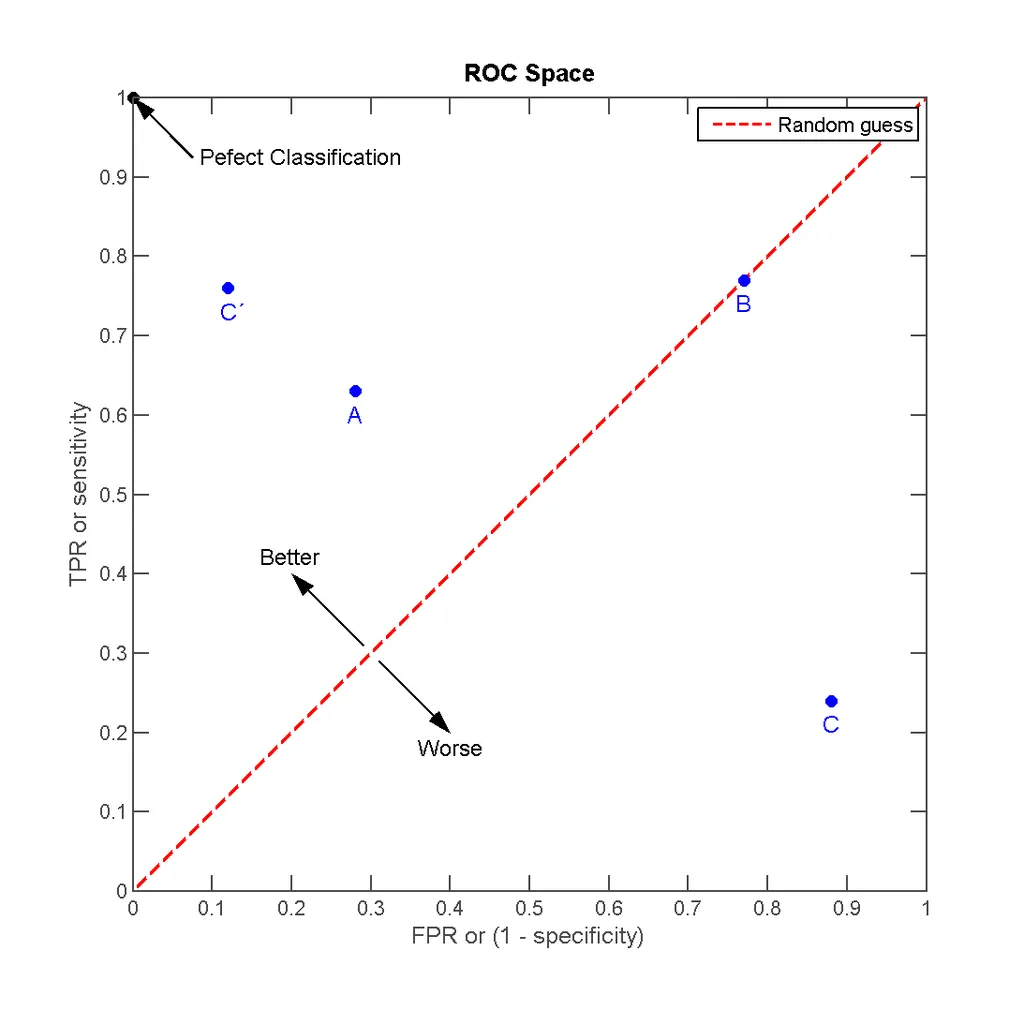 假设您有几个经过训练的二进制分类器A、B(B的效果不如随机猜测等等……),以及一个由n个测试样本和所有这些分类器一起使用的测试集。由于精度和召回率是为所有n个样本计算的,因此与分类器相对应的那些点是有意义的。
假设您有几个经过训练的二进制分类器A、B(B的效果不如随机猜测等等……),以及一个由n个测试样本和所有这些分类器一起使用的测试集。由于精度和召回率是为所有n个样本计算的,因此与分类器相对应的那些点是有意义的。
现在有时人们会谈论ROC曲线,我理解精度是作为召回率的函数来表示的,或者仅仅绘制了Precision(Recall)。
我不明白这种变异性来自何处,因为您有一定数量的测试样本。您只是选择测试集的一些子集,并找到精度和召回率以便绘制它们,从而获得许多离散值(或插值线)吗?
假设您有几个经过训练的二进制分类器A、B(B的效果不如随机猜测等等……),以及一个由n个测试样本和所有这些分类器一起使用的测试集。由于精度和召回率是为所有n个样本计算的,因此与分类器相对应的那些点是有意义的。现在有时人们会谈论ROC曲线,我理解精度是作为召回率的函数来表示的,或者仅仅绘制了Precision(Recall)。
我不明白这种变异性来自何处,因为您有一定数量的测试样本。您只是选择测试集的一些子集,并找到精度和召回率以便绘制它们,从而获得许多离散值(或插值线)吗?