我正在尝试使用Pandas将两列转换为一个列,该列是两个转换列的字典表示。
基本上,我想合并
我知道如何将一行转换为字典表示,但我不确定如何在没有for循环的情况下对所有行执行此操作:
稍后我希望能够根据
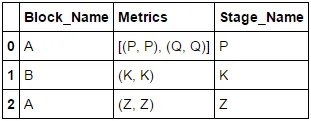
df = DataFrame({'Metrics' : [[("P", "P"), ("Q","Q")], ("K", "K"), ("Z", "Z")],
'Stage_Name' : ["P", "K", "Z"],
'Block_Name' : ["A", "B", "A"]})
基本上,我想合并
Metrics 和 Stage_Name:
将其合并到另一个名为merged的列中,例如,第一行将是:
{'P': [('P', 'P'), ('Q', 'Q')]}
我知道如何将一行转换为字典表示,但我不确定如何在没有for循环的情况下对所有行执行此操作:
something = df.iloc[[0]].set_index('Stage_Name')['Metrics'].to_dict()
print something
Output: {'P': [('P', 'P'), ('Q', 'Q')]}
稍后我希望能够根据
Block_Name 进行聚合,因此对于合并的列,Block_Name 为 A 的两个字典将被相加。{'P': [('P', 'P'), ('Q', 'Q')], 'Z' : [('Z', 'Z')] }
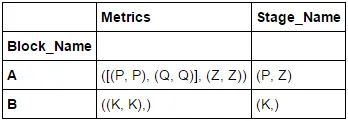
对于Stage_Name和Metrics,我会将它们附加到一个列表中,该列表如下:
grouped = df.groupby(df['Block_Name'])
df_2 = grouped.aggregate(lambda x: tuple(x))
有人能指点我正确的方向吗?谢谢!