以下是时序表:
选项1
pir0 = lambda dfb: pd.get_dummies(dfb.Name).T.dot(
dfb.Product.str.title().str.get_dummies(','))
pir0(dfb)
Apple Banana Orange Pear
Bob 0 1 0 0
Connie 0 0 0 1
John 0 1 1 0
Mike 1 0 0 1
Option 2
选项二
from cytoolz import concat
def pir1(dfb):
f0, u0 = pd.factorize(dfb.Name.values)
p = [x.title().split(',') for x in dfb.Product.values.tolist()]
l = [len(y) for y in p]
f1, u1 = pd.factorize(list(concat(p)))
n, m = u0.size, u1.size
return pd.DataFrame(
np.bincount(f0.repeat(l) * m + f1, minlength=n * m).reshape(n, m),
u0, u1)
pir1(dfb)
Apple Pear Orange Banana
Mike 1 1 0 0
John 0 0 1 1
Bob 0 0 0 1
Connie 0 1 0 0
Option 3
def pir2(dfb):
f0, u0 = pd.factorize(dfb.Name.values)
p = [x.title().split(',') for x in dfb.Product.values.tolist()]
l = [len(y) for y in p]
f1, u1 = pd.factorize(list(concat(p)))
n, m = u0.size, u1.size
a = np.zeros((n, m), dtype=int)
a[f0.repeat(l), f1] = 1
return pd.DataFrame(a, u0, u1)
pir2(dfb)
Apple Pear Orange Banana
Mike 1 1 0 0
John 0 0 1 1
Bob 0 0 0 1
Connie 0 1 0 0
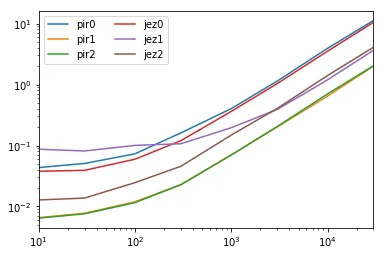
时间
以下是代码
results = pd.DataFrame(
index=pd.Index([10, 30, 100, 300, 1000, 3000, 10000, 30000]),
columns='pir0 pir1 pir2 jez0 jez1 jez2'.split()
)
for i in results.index:
d = pd.concat([dfb] * i, ignore_index=True)
for j in results.columns:
stmt = '{}(d)'.format(j)
setp = 'from __main__ import d, {}'.format(j)
results.set_value(i, j, timeit(stmt, setp, number=20))
ax = results.plot(loglog=True)
ax.legend(ncol=2)
pir0 = lambda dfb: pd.get_dummies(dfb.Name).T.dot(dfb.Product.str.title().str.get_dummies(',')).astype(bool).astype(int)
from cytoolz import concat
def pir1(dfb):
f0, u0 = pd.factorize(dfb.Name.values)
p = [x.title().split(',') for x in dfb.Product.values.tolist()]
l = [len(y) for y in p]
f1, u1 = pd.factorize(list(concat(p)))
n, m = u0.size, u1.size
return pd.DataFrame(
np.bincount(f0.repeat(l) * m + f1, minlength=n * m).reshape(n, m).astype(bool).astype(int),
u0, u1)
def pir2(dfb):
f0, u0 = pd.factorize(dfb.Name.values)
p = [x.title().split(',') for x in dfb.Product.values.tolist()]
l = [len(y) for y in p]
f1, u1 = pd.factorize(list(concat(p)))
n, m = u0.size, u1.size
a = np.zeros((n, m), dtype=int)
a[f0.repeat(l), f1] = 1
return pd.DataFrame(a, u0, u1)
jez0 = lambda dfb: dfb.set_index('Name').Product.str.get_dummies(',')
jez1 = lambda dfb: pd.get_dummies(
dfb.set_index('Name').Product.str.split(',', expand=True),
prefix='', prefix_sep='').groupby(axis=1, level=0).sum()
def jez2(dfb):
mlb = MultiLabelBinarizer()
return pd.DataFrame(
mlb.fit_transform(dfb.Product.str.split(',')),
dfb.Name, mlb.classes_
)
Name列中是否存在重复的值,例如下一行是4 Connie Orange? - jezrael