我有一个时间序列数据集,看起来有点像
ts userid v1 v2
2016-04-23 10:50:12 100001 10 ac
2016-04-23 11:23:29 100002 11 ad
2016-04-23 11:56:57 100002 11 ad
2016-04-23 12:33:38 100001 12 ae
2016-04-23 13:06:43 100001 13 aa
2016-04-23 14:16:34 100001 14 ag
2016-04-23 15:26:39 100002 15 ab
2016-04-23 23:29:31 100003 23 aw
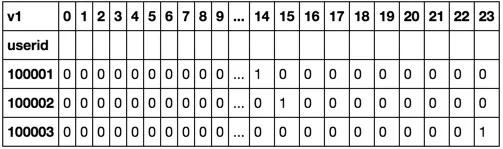
我希望提取每个用户的 v1 计数,并将其放入一个类似于下面的新 DataFrame 中:
userid v1_0 ... v1_10 v1_11 v1_12 v1_13 v1_14 v1_15 ... v1_23
100001 0 ... 1 0 1 1 1 0 ... 0
100002 0 ... 0 2 0 0 0 1 ... 0
100003 0 ... 0 0 0 0 0 0 ... 1
v1表示一天中的小时数(最多24个值),因此意味着需要添加24列新列v2表示事件类型v1_11的值为2,因为在上午11点到中午12点之间有2个事件,用户ID为100002
请问有人能够建议如何使用pandas实现这一目标吗?
提前致谢。
以下是重建原始DataFrame的代码片段:
import pandas as pd
l1 = ['2016-04-23 10:50:12', '2016-04-23 11:23:29', '2016-04-23 11:56:57',
'2016-04-23 12:33:38', '2016-04-23 13:06:43', '2016-04-23 14:16:34',
'2016-04-23 15:26:39', '2016-04-23 23:29:31']
l2 = [100001, 100002, 100002, 100001, 100001, 100001, 100002, 100003]
l3 = [10, 11, 11, 12, 13, 14, 15, 23]
l4 = ['ac','ad','ad','ae', 'aa','ag', 'ab', 'aw']
df = pd.DataFrame({'ts':l1, 'userid':l2, 'v1':l3, 'v2':l4})