一种优雅的方法,可以返回格式漂亮的序列,即将
pandas.Series.value_counts 和
pandas.DataFrame.stack 结合起来使用。
对于 DataFrame:
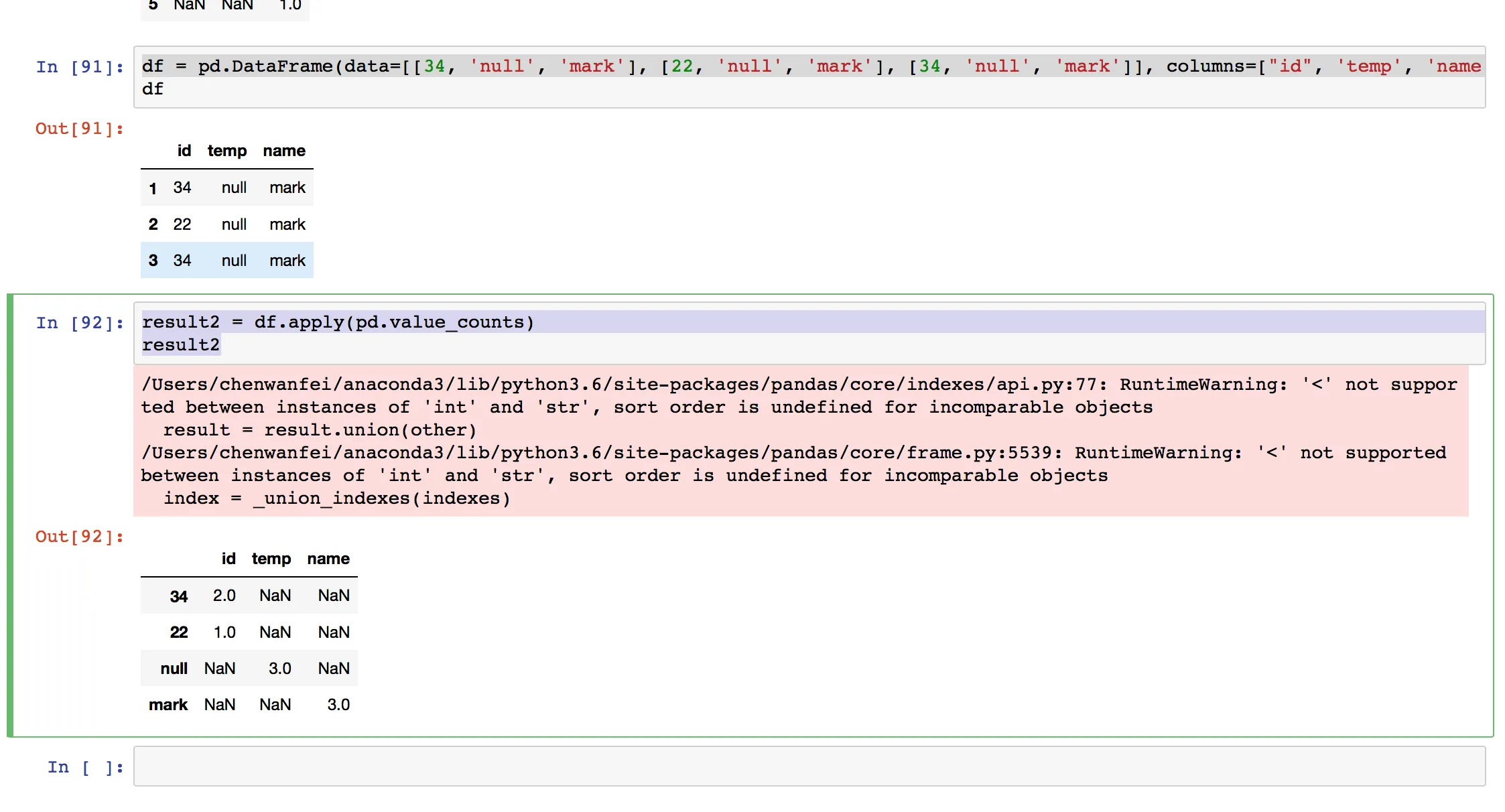
df = pandas.DataFrame(data=[[34, 'null', 'mark'], [22, 'null', 'mark'], [34, 'null', 'mark']], columns=['id', 'temp', 'name'], index=[1, 2, 3])
您可以尝试如下操作:
df.apply(lambda x: x.value_counts()).T.stack()
在这段代码中,
df.apply(lambda x: x.value_counts()) 对每一列应用
value_counts 并将其附加到生成的
DataFrame 中,因此您会得到一个具有相同列和每个列中每个不同值的一行(对于在每个列中没有出现的每个值的每个值都是
null)的
DataFrame。
之后,T 转置了 DataFrame(因此您得到了一个索引等于列且列等于可能值的DataFrame),stack 将 DataFrame 的列转换为 MultiIndex 的新级别,并 "删除" 所有 null 值,使整个内容变成了一个 Series。
这样做的结果是
id 22 1
34 2
temp null 3
name mark 3
dtype: float64
value_counts? - jorisvalue_counts方法,但是与索引对齐有一些问题。 - TomAugspurger