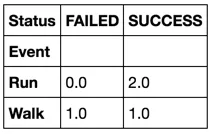
另一种解决方案是使用pivot_table()方法:
In [5]: df.pivot_table(index='Event', columns='Status', aggfunc=len, fill_value=0)
Out[5]:
Status FAILED SUCCESS
Event
Run 0 2
Walk 1 1
针对700K个数据框的时间:
In [74]: df.shape
Out[74]: (700000, 2)
In [75]:
In [76]: %%timeit
....: pd.crosstab(df.Event, df.Status)
....:
1 loop, best of 3: 333 ms per loop
In [77]:
In [78]: %%timeit
....: df.groupby('Event').Status.value_counts().unstack().fillna(0)
....:
1 loop, best of 3: 325 ms per loop
In [79]:
In [80]: %%timeit
....: df.pivot_table(index='Event', columns='Status',
....: aggfunc=len, fill_value=0)
....:
1 loop, best of 3: 367 ms per loop
In [81]:
In [82]: %%timeit
....: (df.assign(ones = np.ones(len(df)))
....: .pivot_table(index='Event', columns='Status',
....: aggfunc=np.sum, values = 'ones')
....: )
....:
1 loop, best of 3: 264 ms per loop
In [83]:
In [84]: %%timeit
....: unq1,ID1 = np.unique(df['Event'],return_inverse=True)
....: unq2,ID2 = np.unique(df['Status'],return_inverse=True)
....:
....: tag = ID1*(ID2.max()+1) + ID2
....:
....: out = np.zeros((len(unq1),len(unq2)),dtype=int)
....: unqID, count = np.unique(tag,return_counts=True)
....: np.put(out,unqID,count)
....:
....: df_out = pd.DataFrame(out,columns=unq2)
....: df_out.index = unq1
....:
1 loop, best of 3: 2.25 s per loop
结论:@
ayhan的解决方案目前获胜:
(df.assign(ones = np.ones(len(df)))
.pivot_table(index='Event', columns='Status', values = 'ones',
aggfunc=np.sum, fill_value=0)
)